前一篇文章把PLE啃了,现在来啃一下AdaTT。这篇论文由Meta发表于KDD 2023,是基于PLE的进一步改进。
现有工作
首先,论文肯定了自定义共享和PLE的观点:不同任务之间相关性强弱不一样,有些任务可能非常相关,有些则相关性低;理想的模型应该能动态地学习这些任务间的关系,而不是静态地假定一个固定共享结构。
如果共享过多,可能导致负迁移;如果特定化太多,又会丢失共享带来的益处,尤其对于样本少的任务。需要一个机制自动平衡共享专家与专属专家(task-specific)的成分。
总结了现存方法的各有优点和局限:
- Shared-bottom: 简单,但共享结构固定,容易把不相关任务强制共享,可能产生负迁移。
- MMoE/PLE 等软共享模型引入了专家网络(experts)+门控(gating)来动态组合专家,但一般是共享专家+任务专家,或在一定层次上动态选择模块。
- Cross-Stitch 等网络也是尝试在固定层之间混合,但门控或混合机制可能不够细粒度,不够灵活。
这篇论文的作者认为,PLE这类软共享模型对于不同任务之间,没有明确的区分,任务之间的关系是模糊的,作者希望在任务层级而非特征层集做共享,我理解为就是照搬模块继续往上叠。
模型架构
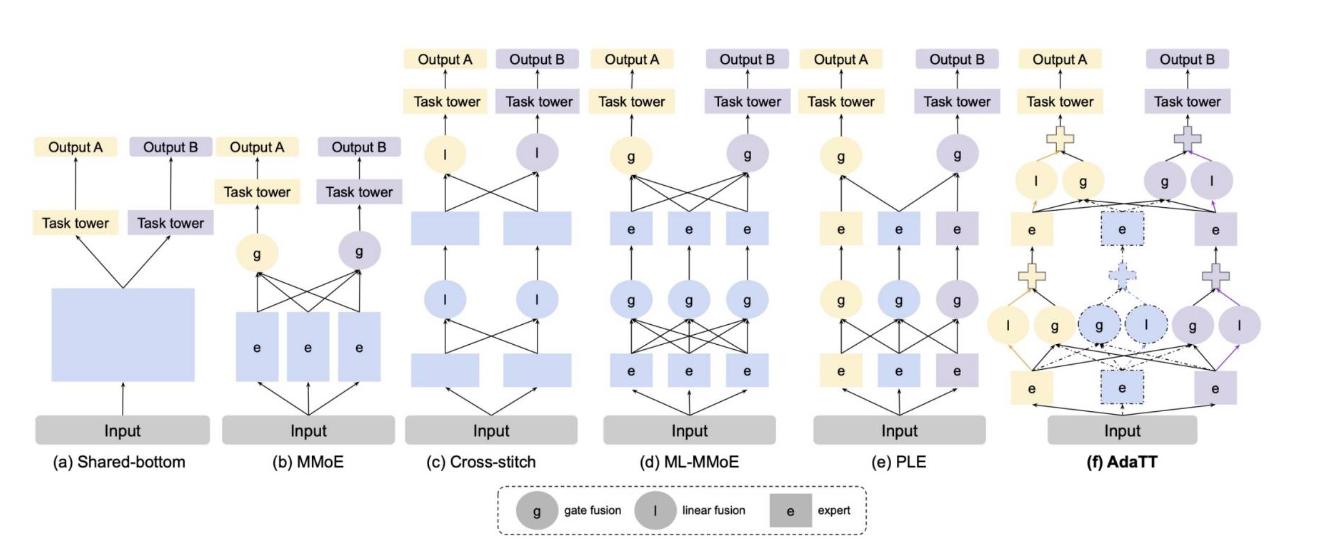
基于上述的观点,这篇论文提出了 AdaTT (Adaptive Task-to-Task Fusion Network),目的是:
- 更精细地建模任务间的关系(task-pair 级别,某一任务与另一任务直接的共享)
- 同时保留任务-特定的学习(task-specific expert),并且以 residual + gating 的方式把共享与专属融合起来,
- 在多层或多深度 (“fusion levels”) 上做融合,以便于浅层学习任务间通用特征,深层学习更任务/语义专属的特征。
代码实现
依旧上meta自己开源的源码,一共给出了两个架构,一个是AdaTTSp,每个任务有独立的专家(expert),每层专家只为对应任务服务。通过门控机制(gate)实现任务间的信息融合。另一个是AdaTTWSharedExps,还引入了“共享专家”(shared experts),所有任务都可以访问共享专家的输出,就跟PLE/MMOE差不多了。
AdaTTSp
import torch
import torch.nn as nn
class AdaTTSp(nn.Module):
"""
paper title: "AdaTT: Adaptive Task-to-Task Fusion Network for Multitask Learning in Recommendations"
paper link: https://doi.org/10.1145/3580305.3599769
Call Args:
inputs: inputs is a tensor of dimension
[batch_size, self.num_tasks, self.input_dim].
Experts in the same module share the same input.
outputs dimensions: [B, T, D_out]
Example::
AdaTTSp(
input_dim=256,
expert_out_dims=[[128, 128]],
num_tasks=8,
num_task_experts=2,
self_exp_res_connect=True,
)
"""
def __init__(
self,
input_dim: int,
expert_out_dims: List[List[int]],
num_tasks: int,
num_task_experts: int,
self_exp_res_connect: bool = True,
activation: str = "RELU",
) -> None:
super().__init__()
# expert_out_dims表示每一层专家网络的隐藏层输出维度。
# [[64, 32]] 表示有1层专家,每个专家是一个两层MLP,第一层输出64维,第二层输出32维
if len(expert_out_dims) == 0:
logger.warning(
"AdaTTSp is noop! size of expert_out_dims which is the number of "
"extraction layers should be at least 1."
)
return
self.num_extraction_layers: int = len(expert_out_dims)
self.num_tasks = num_tasks
self.num_task_experts = num_task_experts
self.total_experts_per_layer: int = num_task_experts * num_tasks
# adatt的改进,用残差连接将每个专家的输出加到融合后的输出
self.self_exp_res_connect = self_exp_res_connect
self.experts = torch.nn.ModuleList()
self.gate_weights = torch.nn.ModuleList()
self_exp_weight_list = []
layer_input_dim = input_dim
# 跟PLE一样,构建每个任务的专家网络
# 专家+门控
for expert_out_dim in expert_out_dims:
self.experts.append(
torch.nn.ModuleList(
[
MLP(layer_input_dim, expert_out_dim, activation)
for i in range(self.total_experts_per_layer)
]
)
)
self.gate_weights.append(
torch.nn.ModuleList(
[
torch.nn.Sequential(
torch.nn.Linear(
layer_input_dim, self.total_experts_per_layer
),
torch.nn.Softmax(dim=-1),
)
for _ in range(num_tasks)
]
)
) # self.gate_weights is of shape L X T, after we loop over all layers.
# 还在每个专家的循环里,会为每个任务的专家初始化一个参数矩阵
if self_exp_res_connect and num_task_experts > 1:
params = torch.empty(num_tasks, num_task_experts)
scale = sqrt(1.0 / num_task_experts)
torch.nn.init.uniform_(params, a=-scale, b=scale)
self_exp_weight_list.append(torch.nn.Parameter(params))
layer_input_dim = expert_out_dim[-1]
self.self_exp_weights = nn.ParameterList(self_exp_weight_list)
def forward(
self,
inputs: torch.Tensor,
) -> torch.Tensor:
for layer_i in range(self.num_extraction_layers):
# all task expert outputs.
# 依旧是压行写法,找到每个任务对应的专家,输出后stack到一起
experts_out = torch.stack(
[
expert(inputs[:, expert_i // self.num_task_experts, :])
for expert_i, expert in enumerate(self.experts[layer_i])
],
dim=1,
) # [B * E (total experts) * D_out]
gates = torch.stack(
[
gate_weight(
inputs[:, task_i, :]
) # W ([B, D]) * S ([D, E]) -> G, dim is [B, E]
for task_i, gate_weight in enumerate(self.gate_weights[layer_i])
],
dim=1,
) # [B, T, E]
# 专家+门控,moe模型的通用写法
fused_experts_out = torch.bmm(
gates,
experts_out,
) # [B, T, E] X [B * E (total experts) * D_out] -> [B, T, D_out]
# adatt的残差连接改进
# 前面为每个专家都初始化了参数矩阵,含义是每个任务对自己所有专家的加权系数
# experts_out.view(experts_out.size(0),self.num_tasks,self.num_task_experts,-1,) 含义是把之前stack拼起来的合并的专家输出,又拆成了每个任务下的每个专家输出
# 然后使用torch.einsum实现了对每个任务自己的专家输出做线性加权
if self.self_exp_res_connect:
# 如果单个任务有多个专家输出,需要有一个参数来让任务选择具体专家的输出
# 所以还是单纯靠增加参数涨点
if self.num_task_experts > 1:
# residual from the linear combination of tasks' own experts.
self_exp_weighted = torch.einsum(
"te,bted->btd",
self.self_exp_weights[layer_i],
experts_out.view(
experts_out.size(0),
self.num_tasks,
self.num_task_experts,
-1,
), # [B * E (total experts) * D_out] -> [B * T * E_task * D_out]
) # bmm: [T * E_task] X [B * T * E_task * D_out] -> [B, T, D_out]
fused_experts_out = (
fused_experts_out + self_exp_weighted
) # [B, T, D_out]
else:
# 每个任务只有一个专家时,直接拟合残差
fused_experts_out = fused_experts_out + experts_out
inputs = fused_experts_out
return inputsAdaTTWSharedExps
AdaTTWSharedExps对AdaTTSp改进了一点,因此只给修改的部分进行了注释:
class AdaTTWSharedExps(nn.Module):
def __init__(
self,
input_dim: int,
expert_out_dims: List[List[int]],
num_tasks: int,
num_shared_experts: int,
num_task_experts: Optional[int] = None,
num_task_expert_list: Optional[List[int]] = None,
# Set num_task_expert_list for experimenting with a flexible number of
# experts for different task_specific units.
self_exp_res_connect: bool = True,
activation: str = "RELU",
) -> None:
super().__init__()
if len(expert_out_dims) == 0:
logger.warning(
"AdaTTWSharedExps is noop! size of expert_out_dims which is the number of "
"extraction layers should be at least 1."
)
return
self.num_extraction_layers: int = len(expert_out_dims)
self.num_tasks = num_tasks
assert (num_task_experts is None) ^ (num_task_expert_list is None)
if num_task_experts is not None:
self.num_expert_list = [num_task_experts for _ in range(num_tasks)]
else:
self.num_expert_list: List[int] = num_task_expert_list
# 这里增加了共享专家
# num_expert_list示例[2, 2, 2, 2, 1]代表每个任务2个专家,1个共享专家,4个任务
self.num_expert_list.append(num_shared_experts)
self.total_experts_per_layer: int = sum(self.num_expert_list)
self.self_exp_res_connect = self_exp_res_connect
self.experts = torch.nn.ModuleList()
self.gate_weights = torch.nn.ModuleList()
layer_input_dim = input_dim
for layer_i, expert_out_dim in enumerate(expert_out_dims):
self.experts.append(
torch.nn.ModuleList(
[
MLP(layer_input_dim, expert_out_dim, activation)
for i in range(self.total_experts_per_layer)
]
)
)
# 如果不是最后一层,就把所有输出(任务专家输出+共享专家)一起传给下一层
# 最后一层只需要每个任务的特征即可,把每个任务塔需要的特征准备好
num_full_active_modules = (
num_tasks
if layer_i == self.num_extraction_layers - 1
else num_tasks + 1
)
self.gate_weights.append(
torch.nn.ModuleList(
[
torch.nn.Sequential(
torch.nn.Linear(
layer_input_dim, self.total_experts_per_layer
),
torch.nn.Softmax(dim=-1),
)
for _ in range(num_full_active_modules)
]
)
) # self.gate_weights is a 2d module list of shape L X T (+ 1), after we loop over all layers.
layer_input_dim = expert_out_dim[-1]
self_exp_weight_list = []
if self_exp_res_connect:
# 计算残差也是需要考虑是否最后一层
# If any tasks have number of experts not equal to 1, we learn linear combinations of native experts.
if any(num_experts != 1 for num_experts in self.num_expert_list):
for i in range(num_tasks + 1):
num_full_active_layer = (
self.num_extraction_layers - 1
if i == num_tasks
else self.num_extraction_layers
)
params = torch.empty(
num_full_active_layer,
self.num_expert_list[i],
)
scale = sqrt(1.0 / self.num_expert_list[i])
torch.nn.init.uniform_(params, a=-scale, b=scale)
self_exp_weight_list.append(torch.nn.Parameter(params))
self.self_exp_weights = nn.ParameterList(self_exp_weight_list)
self.expert_input_idx: List[int] = []
for i in range(num_tasks + 1):
self.expert_input_idx.extend([i for _ in range(self.num_expert_list[i])])
def forward(
self,
inputs: torch.Tensor,
) -> torch.Tensor:
# 同样最后一层前,都在对任务专家和共享专家在做前向传播
for layer_i in range(self.num_extraction_layers):
num_full_active_modules = (
self.num_tasks
if layer_i == self.num_extraction_layers - 1
else self.num_tasks + 1
)
# all task expert outputs.
experts_out = torch.stack(
[
expert(inputs[:, self.expert_input_idx[expert_i], :])
for expert_i, expert in enumerate(self.experts[layer_i])
],
dim=1,
) # [B * E (total experts) * D_out]
# gate weights for fusing all experts.
gates = torch.stack(
[
gate_weight(inputs[:, i, :]) # [B, D] * [D, E] -> [B, E]
for i, gate_weight in enumerate(self.gate_weights[layer_i])
],
dim=1,
) # [B, T (+ 1), E]
# add all expert gate weights with native expert weights.
if self.self_exp_res_connect:
prev_idx = 0
# use_unit_naive_weights来判断所有任务和共享模块的专家数是否都等于1
# 如果每个任务的专家都只有1个,那就不需要加权了,直接加残差
# 如果有多个,才需要之前的初始化权重矩阵,来让模型学习需要为每个专家的输出分配权重
use_unit_naive_weights = all(
num_expert == 1 for num_expert in self.num_expert_list
)
for module_i in range(num_full_active_modules):
next_idx = self.num_expert_list[module_i] + prev_idx
if use_unit_naive_weights:
gates[:, module_i, prev_idx:next_idx] += torch.ones(
1, self.num_expert_list[module_i]
)
else:
gates[:, module_i, prev_idx:next_idx] += self.self_exp_weights[
module_i
][layer_i].unsqueeze(0)
prev_idx = next_idx
fused_experts_out = torch.bmm(
gates,
experts_out,
) # [B, T (+ 1), E (total)] X [B * E (total) * D_out] -> [B, T (+ 1), D_out]
inputs = fused_experts_out
return inputs目前洋洋洒洒写完,感觉也只是在参数量上做了文章,共享专家本身不是新颖的思想,adatt把这个模块从特征提取搬到的任务层面。整体看完,其实还有一些不理解的点,anyway,先在业务上试试效果再决定要不要进一步探索。
2025/9/21 于苏州