相关链接:
25年博客的更新频率慢了很多,一方面是工作量比去年大了,另一方面是学习的方向比以前要更细了。之前什么都看看,属于是样样通样样松(笑)。今年主要聚焦在机器学习,风控方面,内容也偏向论文+代码复现,因此节奏会慢很多。顺便一提,五月假期的时候回了趟西班牙,在那里完成了准备已久的求婚,是人生里的值得回忆的重要节点,这个留到以后再记录。
背景
言归正传,这次要学习的是谷歌团队发表于2018年的MMOE,方向是多任务学习。关于多任务学习,通俗的理解是一个模型学习和预测多个任务,通常来说是反直觉的,因为我们往往只希望模型精准的学习到一个精准具体的任务。不过在很多业务场景下,任务本身有自己的痛点,以消金产品的短信营销为例,算法不光需要考虑用户的点击率,注册率,还需要考虑用户的完件率。电商场景同理,也需要考虑用户的点击率和转化率。
营销场景是一个漏斗场景,用户在每个环节都被层层提纯,这导致后续任务的样本天然就远少于前置任务的样本,这带来了小样本的问题。而我们不想浪费那些在前面几个营销环节折损的用户,并且这几个营销环节作为建模任务的目标是类似的,因此这为多任务学习奠定了基础。
参数共享
已有的多任务学习范式大致分成两类:硬/软参数共享。
硬参数共享
硬参数共享是多任务学习中最符合通俗认知的范式,也就是同一个模型,完整的参数来学习不同的任务,所有任务都用同一套权重来预测。一定意义上,多任务学习类似于迁移学习,通过其他学习其他任务,来最终影响到主任务的预测精度。
软参数共享
软参数共享则类似于每个任务都有自己的参数,而不同任务之间会通过某种方式来对参数进行共享。这样一来,模型在每个任务上都会有着不一样的表示,而不是像硬参数共享用同一套特征。从实现上,类似于多塔+门控网络,其实就是之前学习过的MOE网络。后续的很多改进也都是在这一基础上实现。
论文要点
完整的论文翻译就不摆上来了,重点看下论文的关键部分。MMOE提出于2018年,同年早期阿里巴巴推出了ESMM,两者都是为了解决一个问题:多任务学习里出现的跷跷板效应,也就是当子任务相关性不大时,不同任务的效果会对彼此有影响。因此它们用不同的方法来学习不同任务之间的关系。对于MMOE来说,使用了门控单元来学习不同任务塔的关系。
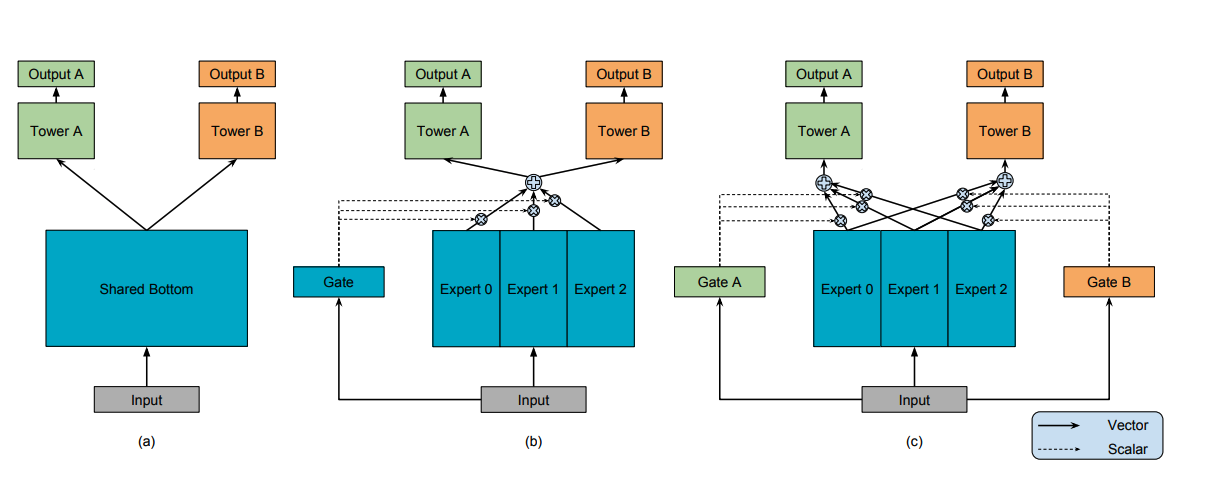
上图展示整个架构的演变经历,图a是一个简单的共享特征的多塔模型,两个任务共享输入的特征表示,走不同的任务的权重来得到最后的结果。随后作者认为不同任务可能会需要不同的特征输入,不能用单一的特征,因此在图b中,用专家网络来为输入加权输出特征,并用一个门控网络来决定不同专家的权重分配,最终用统一的加权过后的特征表示输入给多塔。
图c则更进一步,认为每个任务间,尤其是不相似的任务之间,还是不能完全共享同一套特征,因此为每个任务都分配了一个门控,来定制输入塔的加权特征向量。在实践中,每个门控网络都是一个简单线性层+Softmax,专家和塔都是常规的DNN。
任务相似度的取舍
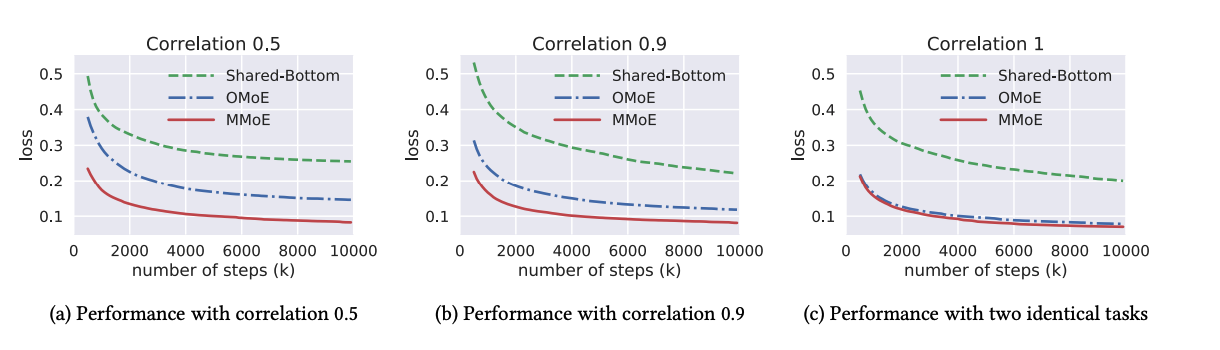
上面的多门控网络比较适用于任务相似度较大的情况,作者在实验里发现任务间余弦相似度=0.5时,网络效果比较好。具体怎么做到这一点,作者自己合成了数据,来控制不同任务的相似程度,如下图所示,多门控专家在任何情况下收敛的都更快,而当子任务越相似时,多门控近似等于单门控,合乎逻辑。
代码实现
MMOE的开源代码不是很多,大部分是tensorflow,这里我以Deepctr-torch版本的源码作为示例debug:
核心部分:
真正的核心架构,去掉注释只有几十行。继承自手搓的BaseModel基类。
import torch
import torch.nn as nn
from ..basemodel import BaseModel
from ...inputs import combined_dnn_input
from ...layers import DNN, PredictionLayer
class MMOE(BaseModel):
"""MMOE实现类
:param dnn_feature_columns: 用于模型中 DNN 部分的所有特征列的集合。
:param num_experts: 整数,专家网络的数量。
:param expert_dnn_hidden_units: 列表,表示每个专家 DNN 的层数和每层的神经元数量。
:param gate_dnn_hidden_units: 列表,表示每个门控网络 DNN 的层数和每层的神经元数量。
:param tower_dnn_hidden_units: 列表,表示每个任务塔 DNN 的层数和每层的神经元数量。
:param l2_reg_linear: float,线性部分的 L2 正则化强度。
:param l2_reg_embedding: float,嵌入向量的 L2 正则化强度。
:param l2_reg_dnn: float,DNN 部分的 L2 正则化强度。
:param init_std: float,用于初始化嵌入向量的标准差。
:param seed: int,随机种子。
:param dnn_dropout: float,[0,1) 范围内的值,表示 DNN 层的 dropout 比例。
:param dnn_activation: DNN 中使用的激活函数。
:param dnn_use_bn: bool,是否在激活函数前使用 BatchNormalization。
:param task_types: 每个任务的类型列表,``"binary"`` 表示二分类损失,``"regression"`` 表示回归损失。例如 ['binary', 'regression']。
:param task_names: 每个任务预测目标的名称。
:param device: str,运行设备,如 ``"cpu"`` 或 ``"cuda:0"``。
:param gpus: 多 GPU 时的设备列表,若为 None 则使用 `device`。`gpus[0]` 应与 `device` 对应。
:return: 一个 PyTorch 模型实例。
"""
def __init__(self, dnn_feature_columns, num_experts=3, expert_dnn_hidden_units=(256, 128),
gate_dnn_hidden_units=(64,), tower_dnn_hidden_units=(64,), l2_reg_linear=0.00001,
l2_reg_embedding=0.00001, l2_reg_dnn=0,
init_std=0.0001, seed=1024, dnn_dropout=0, dnn_activation='relu', dnn_use_bn=False,
task_types=('binary', 'binary'), task_names=('ctr', 'ctcvr'), device='cpu', gpus=None):
super(MMOE, self).__init__(linear_feature_columns=[], dnn_feature_columns=dnn_feature_columns,
l2_reg_linear=l2_reg_linear, l2_reg_embedding=l2_reg_embedding, init_std=init_std,
seed=seed, device=device, gpus=gpus)
self.num_tasks = len(task_names)
if self.num_tasks <= 1:
raise ValueError("num_tasks must be greater than 1")
if num_experts <= 1:
raise ValueError("num_experts must be greater than 1")
if len(dnn_feature_columns) == 0:
raise ValueError("dnn_feature_columns is null!")
if len(task_types) != self.num_tasks:
raise ValueError("num_tasks must be equal to the length of task_types")
for task_type in task_types:
if task_type not in ['binary', 'regression']:
raise ValueError("task must be binary or regression, {} is illegal".format(task_type))
self.num_experts = num_experts
self.task_names = task_names
self.input_dim = self.compute_input_dim(dnn_feature_columns)
self.expert_dnn_hidden_units = expert_dnn_hidden_units
self.gate_dnn_hidden_units = gate_dnn_hidden_units
self.tower_dnn_hidden_units = tower_dnn_hidden_units
# 初始化专家网络
self.expert_dnn = nn.ModuleList([DNN(self.input_dim, expert_dnn_hidden_units, activation=dnn_activation,
l2_reg=l2_reg_dnn, dropout_rate=dnn_dropout, use_bn=dnn_use_bn,
init_std=init_std, device=device) for _ in range(self.num_experts)])
# 初始化门控网络DNN,当len(gate_dnn_hidden_units)=0时,相当于所有特征从专家输出后直接拼接进双塔
if len(gate_dnn_hidden_units) > 0:
self.gate_dnn = nn.ModuleList([DNN(self.input_dim, gate_dnn_hidden_units, activation=dnn_activation,
l2_reg=l2_reg_dnn, dropout_rate=dnn_dropout, use_bn=dnn_use_bn,
init_std=init_std, device=device) for _ in range(self.num_tasks)])
self.add_regularization_weight(
filter(lambda x: 'weight' in x[0] and 'bn' not in x[0], self.gate_dnn.named_parameters()),
l2=l2_reg_dnn)
# 每个任务的门控网络最终层
self.gate_dnn_final_layer = nn.ModuleList(
[nn.Linear(gate_dnn_hidden_units[-1] if len(gate_dnn_hidden_units) > 0 else self.input_dim,
self.num_experts, bias=False) for _ in range(self.num_tasks)])
# 初始化任务塔网络 DNN
if len(tower_dnn_hidden_units) > 0:
self.tower_dnn = nn.ModuleList(
[DNN(expert_dnn_hidden_units[-1], tower_dnn_hidden_units, activation=dnn_activation,
l2_reg=l2_reg_dnn, dropout_rate=dnn_dropout, use_bn=dnn_use_bn,
init_std=init_std, device=device) for _ in range(self.num_tasks)])
self.add_regularization_weight(
filter(lambda x: 'weight' in x[0] and 'bn' not in x[0], self.tower_dnn.named_parameters()),
l2=l2_reg_dnn)
# 每个任务的最终输出层(Logit 层)
self.tower_dnn_final_layer = nn.ModuleList([nn.Linear(
tower_dnn_hidden_units[-1] if len(tower_dnn_hidden_units) > 0 else expert_dnn_hidden_units[-1], 1,
bias=False)
for _ in range(self.num_tasks)])
# 每个任务的预测输出层(含激活函数)
self.out = nn.ModuleList([PredictionLayer(task) for task in task_types])
# 添加正则化权重
regularization_modules = [self.expert_dnn, self.gate_dnn_final_layer, self.tower_dnn_final_layer]
for module in regularization_modules:
self.add_regularization_weight(
filter(lambda x: 'weight' in x[0] and 'bn' not in x[0], module.named_parameters()), l2=l2_reg_dnn)
self.to(device)
def forward(self, X):
# 从特征列提取稀疏嵌入和稠密特征
sparse_embedding_list, dense_value_list = self.input_from_feature_columns(X, self.dnn_feature_columns,
self.embedding_dict)
dnn_input = combined_dnn_input(sparse_embedding_list, dense_value_list)
# 所有专家网络前向传播
expert_outs = []
for i in range(self.num_experts):
expert_out = self.expert_dnn[i](dnn_input)
expert_outs.append(expert_out)
expert_outs = torch.stack(expert_outs, 1) # (批大小, 专家数, 特征维度)
# 每个任务的门控网络前向传播,并加权专家输出
mmoe_outs = []
for i in range(self.num_tasks):
if len(self.gate_dnn_hidden_units) > 0:
gate_dnn_out = self.gate_dnn[i](dnn_input)
gate_dnn_out = self.gate_dnn_final_layer[i](gate_dnn_out)
else:
gate_dnn_out = self.gate_dnn_final_layer[i](dnn_input)
gate_mul_expert = torch.matmul(gate_dnn_out.softmax(1).unsqueeze(1), expert_outs) # (批大小, 1, 特征维度)
mmoe_outs.append(gate_mul_expert.squeeze())# 去掉维度
# 每个任务的塔网络前向传播
task_outs = []
for i in range(self.num_tasks):
if len(self.tower_dnn_hidden_units) > 0:
tower_dnn_out = self.tower_dnn[i](mmoe_outs[i])
tower_dnn_logit = self.tower_dnn_final_layer[i](tower_dnn_out)
else:
tower_dnn_logit = self.tower_dnn_final_layer[i](mmoe_outs[i])
output = self.out[i](tower_dnn_logit)
task_outs.append(output)
# 拼接所有任务的输出
task_outs = torch.cat(task_outs, -1)
return task_outs
2025/5/9 于苏州