在Github上看到一张不错的思维导图,摘录至此:
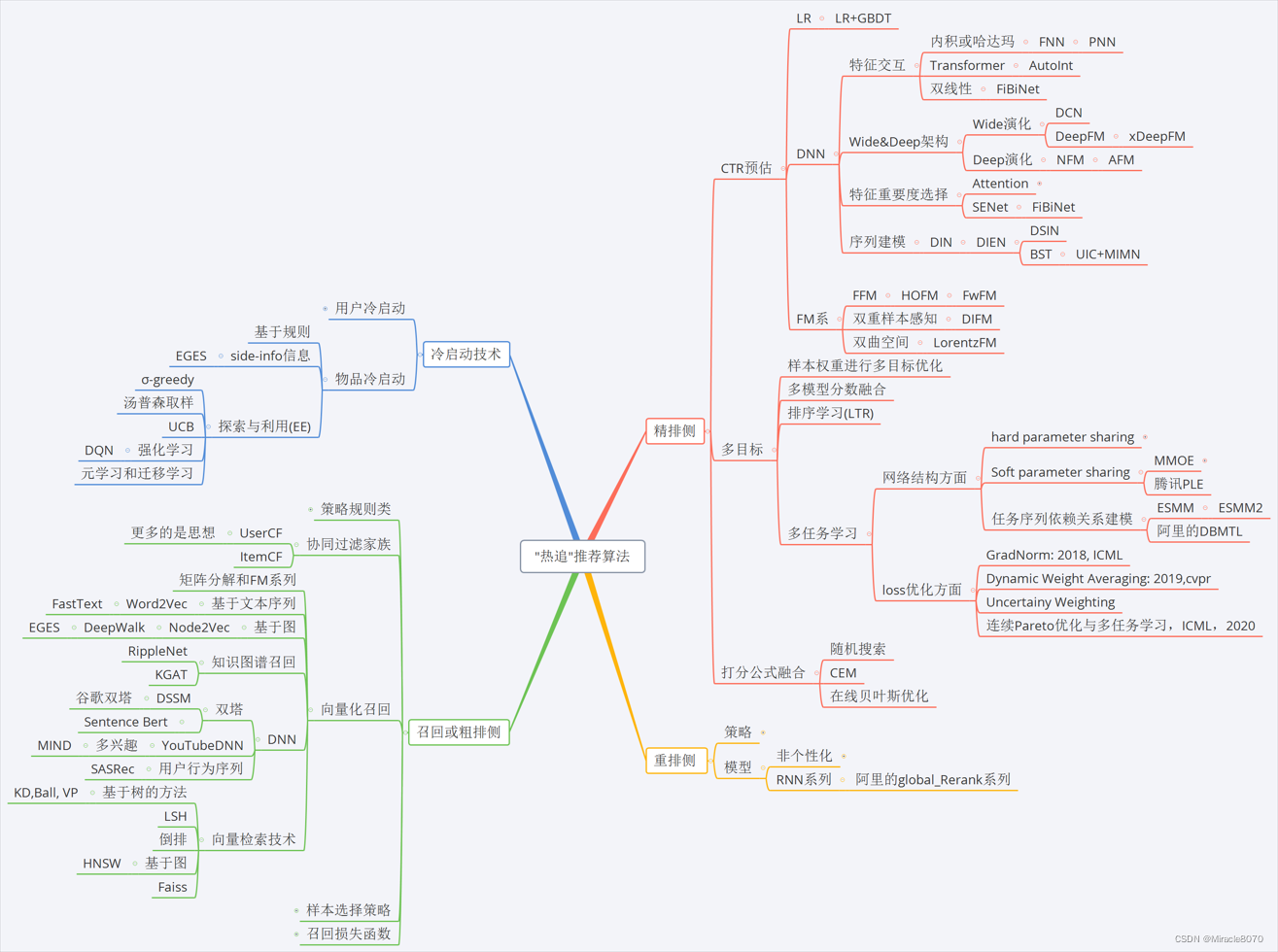
这张图概述了整个推荐系统的学习框架。这次要学习的NeuralCF正属于协同过滤家族下,属于深度学习运用协同过滤的思想诞生的产物。
原论文地址:Neural Collaborative Filtering
翻译论文地址:【翻译】Neural Collaborative Filtering–神经协同过滤
论文思想
原论文发表于2017年,作者的观点是:传统矩阵分解使用隐向量的内积来计算特征交互,这种计算方式可以用神经网络来替代,因为理论上DNN能拟合所有函数,它的表达能力比单纯内积要更好。
简单地将潜在特征的乘积线性组合的内积可能不足以捕捉用户交互数据的复杂结构。
因此作者提出了NCF,名字是神经协同过滤,核心思想是通过一个多层MLP来学习User-Item的交互。
原文用配图展示了共现矩阵对比隐向量(Latent space)的表现能力不足。具体而言是用了一个热门用户,表现为该用户什么都喜欢,使用内积会导致他的相似用户和真实情况有偏差,这实际上是因为只考虑点击的单个维度导致的。现在为了解决这个问题,可以扩大隐向量维度来增加信息。
论文中的实现方式是将输入分成两个部分,GMF和MLP部分。
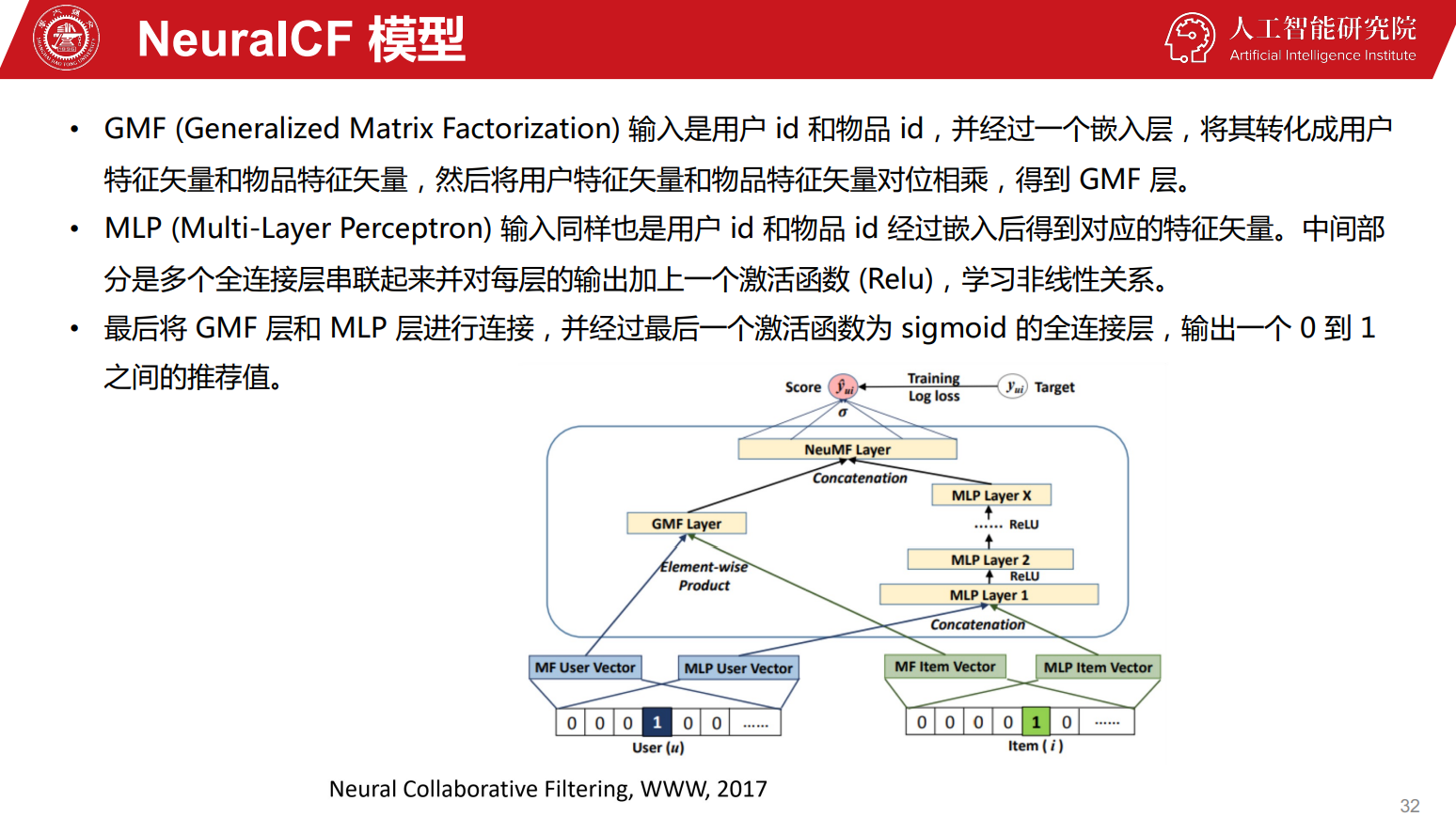
GMF可以视作传统的MF,MLP对User/Item进行更深层的特征提取。
细看一下MLP部分,输入是用户和商品的One Hot编码,经过嵌入后直接Concat后输入网络,得到用户购买商品的概率。
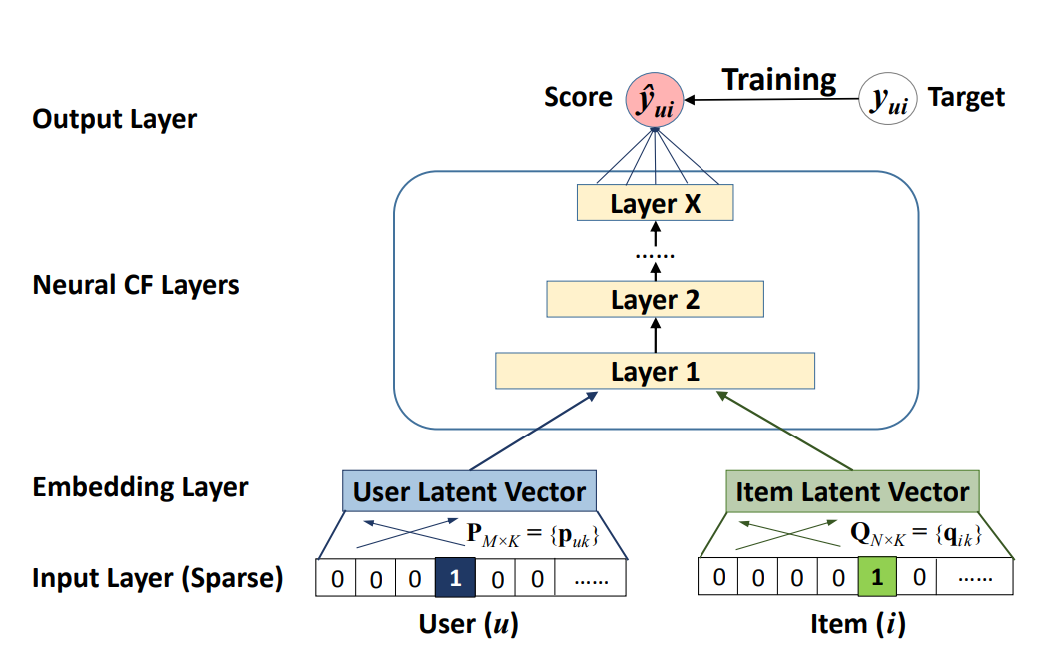
GMF部分的输入也是用户和商品的One Hot编码,经过嵌入后得到User/Item向量$p_{u},q_{i}$。GMF模型的输出则为$\hat y_{ui}=a_{out}(h^{T}(p_{u}\odot q_{i}))$。其中$a_{out}$是激活函数,$h^{T}$是边权重。当激活函数是一个恒等函数,并且权重为1时,GMF就退化为MF模型。
两边其实都用了嵌入层,不过作者将两边分开学习独立的Embedding,并通过连接最后一个隐藏层来组合模型,实际上就是融合了两个模型。在实际融合的时候,使用了一个超参数来权衡两个模型的权重。
不足
模型的输入只有User和Item ID,显然又丢失了很多其他特征,核心还是从共现关系中挖掘更多的信息。完全利用嵌入导致可解释性远远不如特征更多的LR以及各种树模型。
代码实现
使用经典数据集MovieLens作为测试数据集。
import pandas as pd
import numpy as np
import torch
import random
from copy import deepcopy
from torch.utils.data import DataLoader, Dataset读一下文件,然后需要做一些预处理。MovieLens的用户/物品Index是从1开始计数的,我们需要调整到从0开始。
data_root = r'C:\Users\ZeroLoveSeA\Desktop\Datasets\ml-1m'
ml1m_dir = data_root + r'\ratings.dat'
ml1m_rating = pd.read_csv(ml1m_dir, sep='::', header=None, names=['uid', 'mid', 'rating', 'timestamp'], engine='python')
ml1m_rating['userId'], _ = pd.factorize(ml1m_rating['uid'])
ml1m_rating['itemId'], _ = pd.factorize(ml1m_rating['mid'])
ml1m_rating = ml1m_rating[['userId', 'itemId', 'rating', 'timestamp']]
print('Range of userId is [{}, {}]'.format(ml1m_rating.userId.min(), ml1m_rating.userId.max()))
print('Range of itemId is [{}, {}]'.format(ml1m_rating.itemId.min(), ml1m_rating.itemId.max()))
# Range of userId is [0, 6039]
# Range of itemId is [0, 3705]写一下Dataset:
class NCFData(Dataset):
def __init__(self, user_tensor, item_tensor, rating_tensor):
self.user_tensor = user_tensor
self.item_tensor = item_tensor
self.target_tensor = rating_tensor
def __len__(self):
return len(self.user_tensor)
def __getitem__(self, idx):
return self.user_tensor[idx], self.item_tensor[idx], self.target_tensor[idx]然后是DataLoader,我们为每个正样本分配一定数量的负样本,并且需要对评分进行二值化。除此之外,再写一个验证数据集的属性,可以在eval的时候直接调用。
# SampleGenerator
class SampleGenerator:
def __init__(self, ratings):
self.ratings = ratings
self.preprocess_ratings = self._binarize(self.ratings)
self.user_pool = set(self.ratings['userId'].unique())
self.item_pool = set(self.ratings['itemId'].unique())
self.negatives = self._sample_negative(self.ratings)
self.train_ratings, self.test_ratings = self._split_loo(self.preprocess_ratings)
def _binarize(self, ratings):
'''将评分二值化,大于0的评分映射为1'''
ratings['rating'] = (ratings['rating'] > 0).astype(float)
return ratings
def _sample_negative(self, ratings):
'''负采样'''
interact_status = ratings.groupby('userId')['itemId'].apply(set).reset_index().rename(
columns={'itemId': 'interacted_items'})
# 将用户没有交互过的物品作为负样本
interact_status['negative_items'] = interact_status['interacted_items'].apply(lambda x: self.item_pool - x)
# 从负样本中随机采样99个
interact_status['negative_samples'] = interact_status['negative_items'].apply(lambda x: random.sample(list(x), 99))
return interact_status[['userId', 'negative_items', 'negative_samples']]
def _split_loo(self, ratings):
"""Leave-One-Out evaluation"""
ratings['rank_latest'] = ratings.groupby(['userId'])['timestamp'].rank(method='first', ascending=False)
test = ratings[ratings['rank_latest'] == 1]
train = ratings[ratings['rank_latest'] > 1]
assert train['userId'].nunique() == test['userId'].nunique(), 'Not Match Train User with Test User'
return train[['userId', 'itemId', 'rating']], test[['userId', 'itemId', 'rating']]
def instance_a_train_loader(self, num_negatives, batch_size):
'''构建训练数据集'''
print('Load train data')
users, items, ratings = [], [], []
print('Sample negative items')
for row in self.train_ratings.itertuples():
users.append(int(row.userId))
items.append(int(row.itemId))
ratings.append(float(row.rating))
negatives = random.sample(self.negatives[self.negatives['userId'] == row.userId]['negative_samples'].iloc[0], num_negatives)
for i in range(num_negatives):
users.append(row.userId)
items.append(negatives[i])
ratings.append(0) # 负样本的评分为0
print('Construct DataLoader')
dataset = NCFData(user_tensor=torch.tensor(users), item_tensor=torch.tensor(items), rating_tensor=torch.tensor(ratings))
return DataLoader(dataset, batch_size=batch_size, shuffle=True)
@property
def evaluate_data(self):
'''构建测试数据集'''
test_ratings = self.test_ratings.merge(self.negatives[['userId', 'negative_samples']], on='userId')
test_users, test_items, negative_users, negative_items = [], [], [], []
for row in test_ratings.itertuples():
test_users.append(row.userId)
test_items.append(row.itemId)
negative_users.extend([row.userId] * len(row.negative_samples))
negative_items.extend(row.negative_samples)
return [torch.tensor(test_users), torch.tensor(test_items),
torch.tensor(negative_users), torch.tensor(negative_items)]实例化一下Dataloader和验证数据:
sample_generator = SampleGenerator(ml1m_rating)
evaluate_data = sample_generator.evaluate_data接下来写模型,包括forward,train和evaluate。模型架构本身没什么说的,基本上就是Embedding进两个网络,最后Concat后进Sigmoid得到一个Logit。
训练包括了训练单个batch和一个epoch的部分。验证时计算命中率和NDCG。命中率的计算方式是,只要预测的正样本在排名Top k中,则分子+1,分母为所有预测数。NDCG是DCG的归一化,每个样本单独计算其贡献度,即分子为当前样本是否为正样本,是则为1。分母是对样本的index+1取log,也就是当前样本越靠后,分母越大,样本的整体得分越小,相当于一个加权计算。最后将每个样本的贡献度求和,就是DCG。
要求得NDCG,需要对DCG除以一个标准化的系数,IDCG,IDCG和DCG基本一致,只不过分子是理想下的DCG值,即样本真实的DCG值。最终,如果预测和理想完全一致,NDCG的值为1。
import torch
from torch import nn
import math
from tensorboardX import SummaryWriter
class NeuMF(nn.Module):
def __init__(self, num_users, num_items, latent_dim_mf, latent_dim_mlp, config_layers, learning_rate):
super(NeuMF, self).__init__()
self.num_users = num_users
self.num_items = num_items
self.latent_dim_mf = latent_dim_mf
self.latent_dim_mlp = latent_dim_mlp
self.config_layers = config_layers
self.learning_rate = learning_rate
self._writer = SummaryWriter(log_dir='logs')
# 嵌入层
self.embedding_user_mlp = nn.Embedding(num_embeddings=self.num_users, embedding_dim=self.latent_dim_mlp)
self.embedding_item_mlp = nn.Embedding(num_embeddings=self.num_items, embedding_dim=self.latent_dim_mlp)
self.embedding_user_mf = nn.Embedding(num_embeddings=self.num_users, embedding_dim=self.latent_dim_mf)
self.embedding_item_mf = nn.Embedding(num_embeddings=self.num_items, embedding_dim=self.latent_dim_mf)
# MLP layers: 输入层是用户和物品的嵌入向量,输出层是一个数值
self.fc_layers = nn.ModuleList()
input_size = self.latent_dim_mlp * 2 # 合并用户和物品的嵌入向量
for output_size in self.config_layers:
self.fc_layers.append(nn.Linear(input_size, output_size))
input_size = output_size
# Output layer: 输出层的输入是MLP的输出和MF的输出
self.output_layer = nn.Linear(self.config_layers[-1] + self.latent_dim_mf, 1)
# 损失函数和优化器
self.loss = nn.BCELoss()
self.optimizer = torch.optim.Adam(self.parameters(), lr=self.learning_rate)
# 评估指标
self._metrics = Metrics(top_k=10)
# 初始化权重
self._init_weight_()
def _init_weight_(self):
nn.init.normal_(self.embedding_user_mlp.weight, std=0.01)
nn.init.normal_(self.embedding_item_mlp.weight, std=0.01)
nn.init.normal_(self.embedding_user_mf.weight, std=0.01)
nn.init.normal_(self.embedding_item_mf.weight, std=0.01)
for fc in self.fc_layers:
nn.init.xavier_uniform_(fc.weight)
nn.init.zeros_(fc.bias)
nn.init.kaiming_uniform_(self.output_layer.weight, nonlinearity='sigmoid')
nn.init.zeros_(self.output_layer.bias)
def forward(self, user, item):
# MLP part
user_mlp = self.embedding_user_mlp(user)
item_mlp = self.embedding_item_mlp(item)
mlp_vector = torch.cat([user_mlp, item_mlp], dim=-1)
for fc in self.fc_layers:
mlp_vector = torch.relu(fc(mlp_vector))
# MF part
user_mf = self.embedding_user_mf(user)
item_mf = self.embedding_item_mf(item)
mf_vector = torch.mul(user_mf, item_mf)
# 合并MLP和MF的输出
output_vector = torch.cat([mlp_vector, mf_vector], dim=-1)
# 最终输出
rating_logit = torch.sigmoid(self.output_layer(output_vector))
return rating_logit
def train_single_batch(self, users, items, ratings):
if torch.cuda.is_available():
users, items, ratings = users.cuda(), items.cuda(), ratings.cuda()
self.train()
self.optimizer.zero_grad()
ratings_pred = self.forward(users, items)
loss = self.loss(ratings_pred.view(-1), ratings)
loss.backward()
self.optimizer.step()
return loss.item()
def train_single_epoch(self, train_loader, epoch_id):
self.train()
total_loss = 0
for batch_id, (users, items, ratings) in enumerate(train_loader):
loss = self.train_single_batch(users, items, ratings)
print('Epoch {} Batch {} Loss {}'.format(epoch_id, batch_id, loss))
total_loss += loss
self._writer.add_scalar('model/loss', total_loss, epoch_id)
return total_loss
def evaluate(self, evaluate_data):
self.eval()
test_users, test_items, negative_users, negative_items = evaluate_data
if torch.cuda.is_available():
test_users, test_items, negative_users, negative_items = test_users.cuda(), test_items.cuda(), negative_users.cuda(), negative_items.cuda()
# 计算测试样本和负样本的预测分数
test_scores = self.forward(test_users, test_items)
negative_scores = self.forward(negative_users, negative_items)
# 设置 metrics 中的 subjects
self._metrics.set_subjects(
test_users=test_users.cpu(),
test_items=test_items.cpu(),
test_scores=test_scores.cpu(),
negative_users=negative_users.cpu(),
negative_items=negative_items.cpu(),
negative_scores=negative_scores.cpu()
)
# 计算命中率和NDCG
hit_ratio = self._metrics.cal_hit_ratio()
ndcg = self._metrics.cal_ndcg()
self._writer.add_scalar('model/hit_ratio', hit_ratio, 0)
self._writer.add_scalar('model/ndcg', ndcg, 0)
print('Hit Ratio is {:.6f}, NDCG is {:.6f}'.format(hit_ratio, ndcg))
return hit_ratio, ndcg
class Metrics(object):
def __init__(self, top_k):
self._top_k = top_k
def set_subjects(self, test_users, test_items, test_scores, negative_users, negative_items, negative_scores):
self._subjects = []
for i in range(len(test_users)):
user = test_users[i].item()
test_item = test_items[i].item()
# test_score 是一维的
test_score = test_scores[i].view(-1).item() # 确保 test_score 是标量
# neg_items 是负样本的物品ID
neg_items = negative_items[i*99:(i+1)*99].detach().numpy()
# neg_scores 是针对负样本的评分,需展平为一维
neg_scores = negative_scores[i*99:(i+1)*99].view(-1).detach().numpy()
# 合并正样本和负样本的物品及其对应分数
items = np.concatenate(([test_item], neg_items))
scores = np.concatenate(([test_score], neg_scores))
# 按得分排序
ranked_idx = np.argsort(-scores)
ranked_items = items[ranked_idx]
self._subjects.append({
'user': user,
'ranked_items': ranked_items,
'test_item': test_item
})
def cal_hit_ratio(self):
hits = 0
for subject in self._subjects:
# 如果正样本的物品在排名前top_k之内,则命中
if subject['test_item'] in subject['ranked_items'][:self._top_k]:
hits += 1
return hits / len(self._subjects)
def cal_ndcg(self):
total_ndcg = 0
for subject in self._subjects:
try:
rank = np.where(subject['ranked_items'] == subject['test_item'])[0][0] + 1
total_ndcg += math.log(2) / math.log(1 + rank)
except IndexError:
continue
return total_ndcg / len(self._subjects)
我们训练一个Epoch试一下,设置MF和MLP的隐向量维度都为8,BS为64:
num_users = ml1m_rating['userId'].nunique()
num_items = ml1m_rating['itemId'].nunique()
num_factors_mf = 8
num_factors_mlp = 8
layers = [16, 64, 32, 16, 8]
learning_rate = 0.001
batch_size = 64
num_negatives = 4
neumf = NeuMF(num_users=num_users,
num_items=num_items,
latent_dim_mf=num_factors_mf,
latent_dim_mlp=num_factors_mlp,
config_layers=layers,
learning_rate=learning_rate)
if torch.cuda.is_available():
neumf = neumf.cuda()
for epoch in range(1):
train_loader = sample_generator.instance_a_train_loader(num_negatives, batch_size)
loss = neumf.train_single_epoch(train_loader, epoch)
hit_ratio, ndcg = neumf.evaluate(evaluate_data)
# Epoch 0 Batch 24 Loss 0.6258940696716309
...
# Epoch 0 Batch 77667 Loss 0.38616734743118286
# Epoch 0 Batch 77668 Loss 0.2662082016468048
# Epoch 0 Batch 77669 Loss 0.12284557521343231
# Hit Ratio is 0.617384, NDCG is 0.4645882024/10/3 于苏州