最近开始重新捡起一些数据库相关的知识,以前学习的内容差不多忘完了,这次刚好算作温习一下。这篇博文记录如何在WSL中部署Apache Hive。
Map-Reduce
要了解Hive,首先要了解Hadoop。要了解Hadoop,就需要先了解Map-Reduce。
Map-Reduce来源于谷歌公司发表于2004的一篇论文。它要解决的是传统数据库中无法解决的大数据量的场景。在过去,传统的关系型数据库中,数据都保存在单机上,随着数据量的增大,只能通过扩展单机配置来扩容。为了解决这个问题,就需要一个分布式框架,让多个主机能分开处理任务,这就是Map-Reduce产生的契机。
Map-Reduce是一个框架,它的工作流程包含两步:Map,Reduce。用户通过编写并行处理的程序,在每台节点上执行,来处理大量的数据。大体上来说,Map过程将数据分割为键值对,随后进行排序及分组,最后由Reduce进行合并,并输出最后的结果。
MapReduce 优点 简化编程模型:开发者只需关注 Map 和 Reduce 函数的实现,并行化和分布式处理由框架处理。 扩展性:可以轻松扩展到数千台计算机,处理 PB 级别的数据。 容错性:框架自动处理任务失败和节点故障,确保任务顺利完成。
MapReduce 缺点 实时性差:需要进行多次磁盘 I/O 操作,MapReduce 适合批处理,不适合实时数据处理。 效率较低:对于某些计算密集型任务的性能不行。
以下一个具体的流程图:
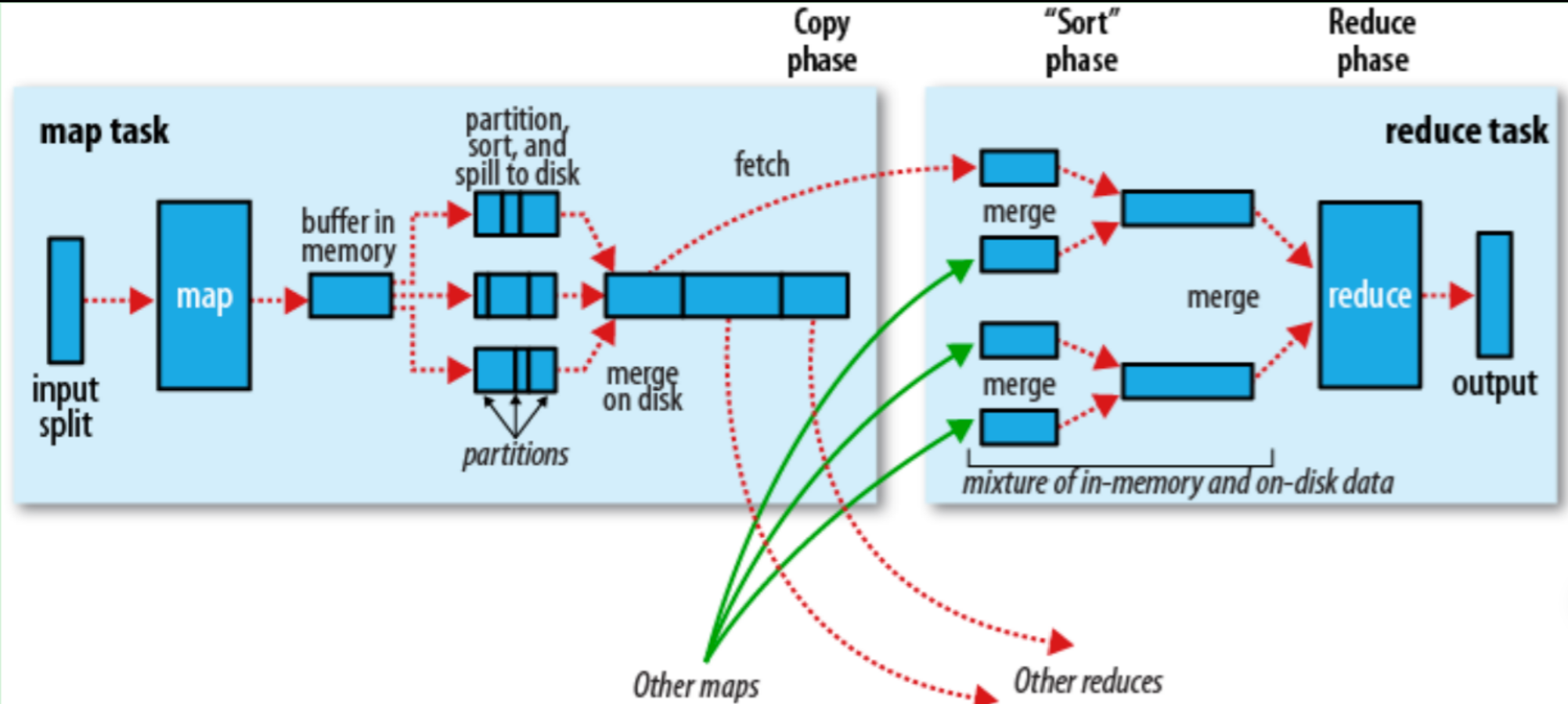
Hadoop
Hadoop是一个用Java编写的开源框架,旨在实现分布式数据处理。它的组件包括了以下:
- Hadoop HDFS:Hadoop 分布式存储系统。
- Yarn:Hadoop 2.x版本开始才有的资源管理系统。
- MapReduce:并行处理框架。
Hadoop的部署
我在Windows的Linux子系统Ubuntu部署Hadoop,由于Hadoop基于Java实现,因此第一步是安装Java。
Java安装
在Ubuntu中安装Java相对简单,这里采用了Java8进行实现:
sudo apt update
sudo apt install openjdk-8-jdk -y下载完成后,设置Java 8 为默认的版本
sudo update-alternatives --config java上述指令能获取到Java的安装路径。获取路径是为了修改环境变量,我们使用vim ~/.bashrc来修改一下配置,加入以下内容:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export PATH=$JAVA_HOME/bin:$PATH完成后需要使更改生效:
source ~/.bashrc使用java -version来检查是否正确安装。
Hadoop安装
我部署的版本是hadoop 3.3.4,首先需要从Apache Hadoop官方网站下载Hadoop的二进制文件。从以下url获取到tar包:Apache Download Mirrors。也可以通过:
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.4.0/hadoop-3.4.0.tar.gz使用tar -xzvf hadoop-3.3.4.tar.gz解压,并移动到一个指定的路径,这里我们放在usr/local/hadoop路径。
tar -xzvf hadoop-3.3.4.tar.gz
sudo mv hadoop-3.3.4 /usr/local/hadoop 同样的需要配置一下环境变量,使用vim ~/.bashrc进行修改并增加以下内容:
# Hadoop Environment Variables
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"使用source ~/.bashrc来应用更改。
Hadoop配置
安装完hadoop后还需要配置一下,需要到$HADOOP_HOME/etc/hadoop目录进行修改:
hadoop-env.sh
需要替换Java环境变量,这里我的路径是/usr/lib/jvm/java-8-openjdk-amd64:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64core-site.xml
默认是空的,需要加上以下内容:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml
用来配置HDFS,因此需要加上配置信息:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/zerolovesea/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/zerolovesea/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>具体的配置项解释如下:
- dfs.replication:定义了HDFS中每个文件块的复制因子。值为
1意味着每个文件块只有一个副本。- dfs.namenode.name.dir:指定了NameNode存储其元数据的本地文件系统路径。元数据包括文件系统的目录结构和文件块的信息。
- dfs.datanode.data.dir:指定了DataNode存储实际数据块的本地文件系统路径。
yarn-site.xml
YARN的配置文件,加入以下内容:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
用于指定使用的MapReduce框架,加入以下内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>验证安装
上述配置完成后就可以直接执行了。执行以下内容:
hdfs namenode -format
start-dfs.sh
start-yarn.sh这样就能够依次启动Hadoop文件系统和Yarn脚本。hdfs namenode -format用来初始化namenode,只需要第一次执行就可以了。
至此Hadoop安装完毕,我们可以通过访问转发后的端口http://localhost:转发端口/来直接访问到Hadoop的服务。
Hive
Hive和Hadoop的关系可能让有些人不太理解,前者实际上是基于后者的一个衍生工具。由于Hadoop由Java编写,当用户需要实现具体功能的时候,需要使用Java来编写MapReduce任务。也就是需要分开写多个Java代码来实现Map和Reduce的功能,这让一些只懂SQL的用户增加了学习成本。
为了解决这个问题,才出现了Hive,它用来将SQL转换为MapReduce任务,以帮助用户更快的实现需求。
Hive的主要组件包括:
- MetaStore: 存储Hive表的元数据。
- HiveQL: 类似于SQL的查询语言。
- 执行引擎: 将HiveQL转换为MapReduce任务,执行数据处理。
Hive的部署
Hive安装
我们选择Hive 3.1.3来安装,在选取版本时,需要注意一定要和安装的Hadoop版本相匹配,不然会出现很多问题。首先下载tar包,通过Index of /hive (apache.org)或:
wget https://dlcdn.apache.org/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz随后解压并移动到需要的路径,例如:
tar -xzvf apache-hive-3.1.3-bin.tar.gz
sudo mv apache-hive-3.1.3-bin /usr/local/hive同时在bashrc中修改环境变量:
# Hive Environment Variables
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin使用source ~/.bashrc使更改生效。
Hive配置
Hive的配置文件位于$HIVE_HOME/conf目录下。
我们需要先执行cp hive-env.sh.template hive-env.sh,并在其中添加Hadoop的路径:
export HADOOP_HOME=/usr/local/hadoop随后,需要创建并修改路径下的hive-site.xml,这是Hive的主要配置文件:
hive-site.xml
默认是没有这个文件的,因此需要创建并添加以下内容:
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/metastore_db?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>zerolovesea</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>zy26yang</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>datanucleus.autoCreateSchema</name>
<value>true</value>
<description>Auto create the JDO tables needed by the metastore</description>
</property>
<property>
<name>hive.server2.enable.doAs</name>
<value>true</value>
</property>
<property>
<name>hive.server2.authentication</name>
<value>NONE</value>
</property>其中有一些是需要自定义的内容,例如:
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>zerolovesea</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>zy26yang</value>
<description>password to use against metastore database</description>
</property>这两段分别用来配置连接数据库时的用户名和密码。
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/metastore_db?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>这段用于配置MySQL的连接,会在后面解释。
Hive元数据存储设置
Hive需要一个元数据存储来保存表和数据库信息。这里我们使用MySQL作为元数据存储。
首先需要安装MySQL:
sudo apt update
sudo apt install mysql-server -y随后登录MySQL并创建数据库以及用户:
sudo mysql -u root -p进入MySQL后,执行以下命令以创建用户名和密码:
CREATE DATABASE metastore_db;
CREATE USER 'zerolovesea'@'localhost' IDENTIFIED BY 'zy26yang';
GRANT ALL PRIVILEGES ON metastore_db.* TO 'zerolovesea'@'localhost';
FLUSH PRIVILEGES;
EXIT;这里的用户名和密码就对应前面Hive配置的内容。
初始化Hive元数据
Hive提供了一个脚本来初始化元数据表。需要下载MySQL JDBC驱动并将其复制到Hive库目录:
wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-8.0.29.tar.gz
tar -xzvf mysql-connector-java-8.0.29.tar.gz
sudo cp mysql-connector-java-8.0.29/mysql-connector-java-8.0.29.jar /usr/local/hive/lib/随后执行以下命令来初始化元数据:
schematool -initSchema -dbType mysql最后启动Hive:
hive
至此大功告成,我们可以创建一个表,插入数据来验证安装是否成功:
CREATE TABLE test (id INT, name STRING);
LOAD DATA LOCAL INPATH '/usr/local/hive/examples/files/kv1.txt' INTO TABLE test;
SELECT * FROM test;我们可以通过SHOW TABLES;来查看当前数据库中的所有表:
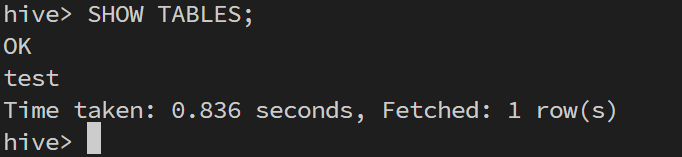
也可以查看其中的内容:
USE database_name;
SHOW TABLES;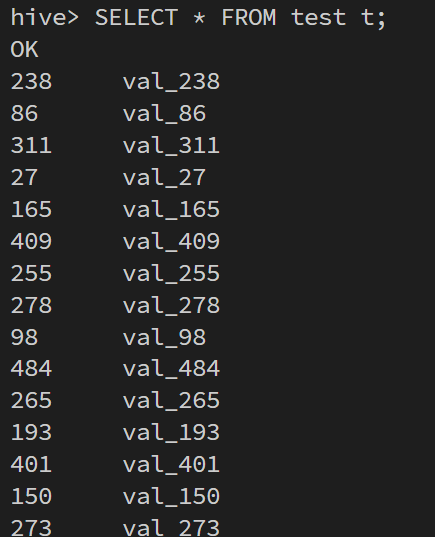
使用DBeaver连接Hive
使用命令行连数据库还是比较麻烦,因此考虑使用DBeaver来连接Hive。要实现它,首先需要让WSL和Windows进行通信。我们在WSL中输出hostname -I来获取WSL的IP地址。
随后在WSL启动HiveServer2:
hiveserver2这时就可以在DBeaver中配置新连接了。在创建新连接中选择Apache Hive,随后连接参数里填上主机,端口,数据库,用户名和密码,就可以连接到WSL的Hive了。
停止服务
如果需要停止服务,需要执行以下内容:
停止Hadoop服务
# 停止YARN
stop-yarn.sh
# 停止HDFS
stop-dfs.sh停止Hive服务
# 停止Hive Metastore
# 如果是以后台方式启动的,需要找到其进程并杀掉
# 举例:
# ps -ef | grep HiveMetaStore
# kill <process_id>
# 停止HiveServer2
# 如果是以后台方式启动的,需要找到其进程并杀掉
# 举例:
# ps -ef | grep HiveServer2
# kill <process_id>关闭WSL
在停止所有服务之后,就可以安全地关闭WSL:
wsl --shutdown这样可以确保Hadoop和Hive服务被优雅地停止,避免数据损坏或任务中断。
重新启动Hadoop和Hive服务
下次启动WSL时,需要重新启动Hadoop和Hive服务:
# 启动HDFS
start-dfs.sh
# 启动YARN
start-yarn.sh
# 启动Hive
# 如果需要HiveServer2或Metastore,也需要分别启动2024/6/9 于苏州