前一篇博客讲了已经被淘汰的数据并行,这次学习一下目前用的比较多的分布式数据并行(Distributed Data Parallel)。对比DP,DDP能够使用于单机多卡和多机多卡,并且对GPU的利用率更佳。
和DP有什么不同?
使用torch.distributed,编写一份训练代码,torch会将代码分配给每个进程。此时就没有主GPU的区别,每个GPU都执行相同的工作。此外,每个GPU加载自己的数据,并且对比DP,反向传播这个过程是在每个GPU上实现的,而不是汇集到主GPU上执行。
训练流程
分布式数据并行的流程如下所示:
- Step 1 使用多进程,每个进程加载模型和数据
- Step2 各进程前向传播,得到输出
- Step3 各进程计算Loss,反向传播并得到梯度
- Step4 各进程通信,梯度在各卡进行同步
- Step5 各进程更新模型
分布式训练中的基本概念
分布式训练中包含了几个基本的概念:
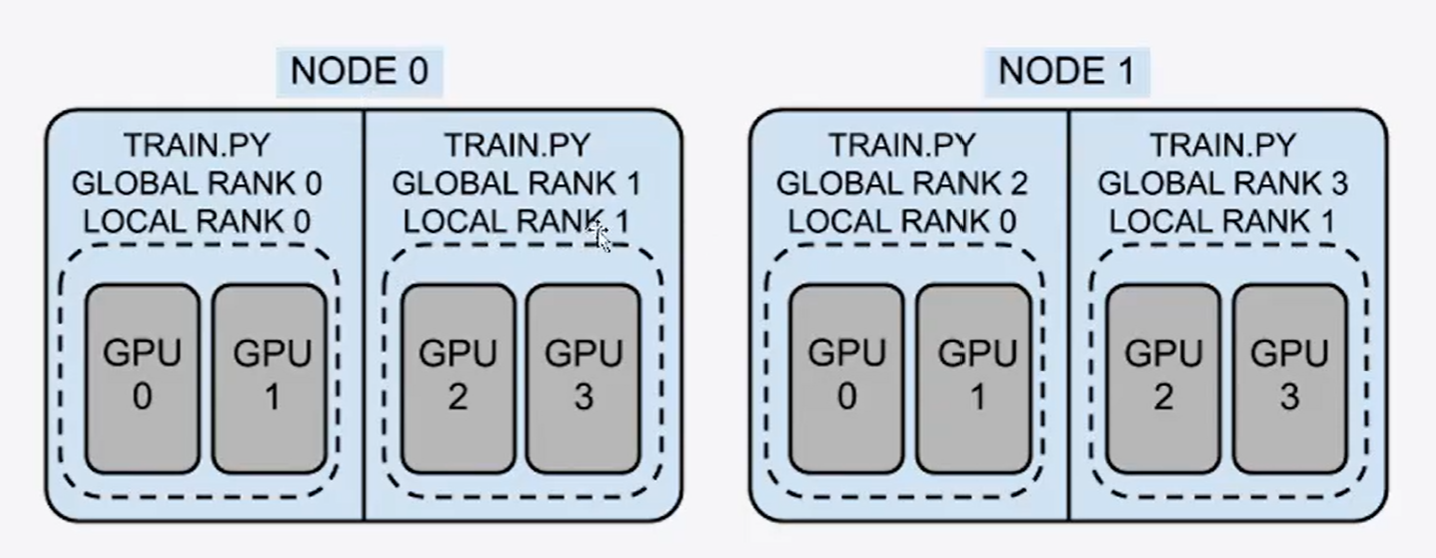
group: 进程组。一个分布式任务对应一个进程组。一般所有的显卡都在一个组里。一个 任务即为一个组,也即一个 world。world_size:全局并行数,一般是总卡数。node:节点。一般是一台机器,或是一个容器。里面会包含多个GPU。rank(global_rank):整个分布式训练任务内的进程序号,一般rank为0指的是主进程。local_rank:区别于rank,是每个节点内部的相对的进程的序号。可以理解为进程内的GPU 编号,例如 rank = 3,local_rank = 0 表示第 3 个进程内的第 1 块 GPU。
例如下图是一个示例:2机4卡的分布式训练。此时node为2,world_size为4。
分布式训练中的通信
分布式训练中,不同节点一般都需要进行信息交换,这就叫做通信。通信被分为两个大类:点对点通信就是将数据从一个进程传输到另一个进程。
集合通信则是指一个分组内所有进程的通信,也就是多卡之间的通信。包含了六种通信类型:
Scatter: 分发。将主进程上Rank 0 上的数据平均分发给其他Rank。Gather: 与Scatter相反,将子进程的数据汇集在主进程。Reduce: 将子进程上的数据合并后,进行某种计算(加减乘除,平均等等)后传到主进程。All Reduce: 将多个进程的信息先汇总并处理/计算后,在将结果发送回每个进程。Broadcast: 将Rank 0上的完整数据广播到各个Rank。All Gather: 将所有进程上的数据汇总(不计算)后,分发到每个进程。这样每个进程都会有一样的完整数据。
Pytorch单机多卡代码实现
使用分布式数据并行需要用python文件进行执行,运行文件也需要使用torchrun的方式来执行。例如下面这个示例代码,需要在命令行运行torchrun --nproc_per_node=2 ddp.py来运行,这代表着使用两个卡来进行训练。nproc_per_node 参数指定为当前主机创建的进程数。一般设定为当前主机的 GPU 数量。
还有一些需要注意的参数:
nproc_per_node指的是每个阶段的进程数nnodes节点数,也就是机器的数量node_rank节点rank,对于第一台机器是0,第二台机器是1master_addr主节点的ipmaster_port主节点的端口号
首先需要进行初始化和导入依赖项:
from transformers import BertTokenizer, BertForSequenceClassification
import torch.distributed as dist
dist.init_process_group(backend="nccl") # 初始化分布式处理组参数backend="nccl"指定了使用NCCL(Nvidia Collective Communications Library)作为后端来实现分布式处理。
接下来是导入数据和准备Dataset等前置工作:
import pandas as pd
data = pd.read_csv("./ChnSentiCorp_htl_all.csv")
data = data.dropna()
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self) -> None:
super().__init__()
self.data = pd.read_csv("./ChnSentiCorp_htl_all.csv")
self.data = self.data.dropna()
def __getitem__(self, index):
return self.data.iloc[index]["review"], self.data.iloc[index]["label"]
def __len__(self):
return len(self.data)
dataset = MyDataset()
import torch
from torch.utils.data import random_split
trainset, validset = random_split(dataset, lengths=[0.9, 0.1], generator=torch.Generator().manual_seed(42)) # 设置种子,在不同进程的数据切分保持一致
len(trainset), len(validset)在准备一下Tokenizer和DataLoader。
tokenizer = BertTokenizer.from_pretrained("/gemini/code/model")
def collate_func(batch):
texts, labels = [], []
for item in batch:
texts.append(item[0])
labels.append(item[1])
inputs = tokenizer(texts, max_length=128, padding="max_length", truncation=True, return_tensors="pt")
inputs["labels"] = torch.tensor(labels)
return inputs
from torch.utils.data import DataLoader
from torch.utils.data.distributed import DistributedSampler
trainloader = DataLoader(trainset, batch_size=32, collate_fn=collate_func, sampler=DistributedSampler(trainset))
validloader = DataLoader(validset, batch_size=64, collate_fn=collate_func, sampler=DistributedSampler(validset))这里的DistributedSampler能够将不同进程上的数据进行分配,并且不会出现重复。对比之前,DataLoader里少了shuffle这个参数,取而代之的是sampler。
接下来是设置模型,我们需要将模型传到各自的GPU上。为了获取当前机器的GPU参数,我们需要从环境变量导入一下参数。
随后用DDP包装一下模型。这样模型就准备好了。
from torch.optim import Adam
import os
from torch.nn.parallel import DistributedDataParallel as DDP
model = BertForSequenceClassification.from_pretrained("/gemini/code/model")
if torch.cuda.is_available():
model = model.to(int(os.environ["LOCAL_RANK"]))
model = DDP(model)
optimizer = Adam(model.parameters(), lr=2e-5)模型准备完,就可以准备训练了。
def print_rank_0(info):
# 在主进程上打印信息
if int(os.environ["RANK"]) == 0:
print(info)
def evaluate():
model.eval()
acc_num = 0
with torch.inference_mode():
for batch in validloader:
if torch.cuda.is_available():
batch = {k: v.to(int(os.environ["LOCAL_RANK"])) for k, v in batch.items()} # 将数据传到显卡
output = model(**batch)
pred = torch.argmax(output.logits, dim=-1)
acc_num += (pred.long() == batch["labels"].long()).float().sum()
dist.all_reduce(acc_num, op=dist.ReduceOP.SUM) # 将各卡的数据汇总到主进程,没有这步会导致精度非常低
return acc_num / len(validset) # 得到评估得分
def train(epoch=3, log_step=100):
global_step = 0
for ep in range(epoch):
model.train()
trainloader.sampler.set_epoch(ep)
for batch in trainloader:
if torch.cuda.is_available():
batch = {k: v.to(int(os.environ["LOCAL_RANK"])) for k, v in batch.items()}
optimizer.zero_grad()
output = model(**batch)
loss = output.loss
loss.backward()
optimizer.step()
if global_step % log_step == 0:
# Loss的通信部分,将Loss求均值,即Opreation为AVG
dist.all_reduce(loss, op=dist.ReduceOp.AVG)
# 在主进程打印损失信息
print_rank_0(f"ep: {ep}, global_step: {global_step}, loss: {loss.item()}")
global_step += 1
acc = evaluate()
print_rank_0(f"ep: {ep}, acc: {acc}")
train()
Trainer单机多卡代码实现
HuggingFace的Trainer代码中同样封装了分布式数据并行,下面是示例代码。运行时也是一样的使用torchrun --nproc_per_node=2 ddp_trainer.py。可以看到其实并没有在代码层面进行修改太多,这是因为Trainer类本身已经内置了分布式训练的判断。
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments, BertTokenizer, BertForSequenceClassification
from datasets import load_dataset
dataset = load_dataset("csv", data_files="./ChnSentiCorp_htl_all.csv", split="train")
dataset = dataset.filter(lambda x: x["review"] is not None)
dataset
datasets = dataset.train_test_split(test_size=0.1, seed=42) # 随机种子一定要设置,否则不同进程会用混数据
datasets
import torch
tokenizer = BertTokenizer.from_pretrained("/gemini/code/model")
def process_function(examples):
tokenized_examples = tokenizer(examples["review"], max_length=128, truncation=True)
tokenized_examples["labels"] = examples["label"]
return tokenized_examples
tokenized_datasets = datasets.map(process_function, batched=True, remove_columns=datasets["train"].column_names)
tokenized_datasets
model = BertForSequenceClassification.from_pretrained("/gemini/code/model")
model.config
import evaluate
acc_metric = evaluate.load("./metric_accuracy.py")
f1_metirc = evaluate.load("./metric_f1.py")
def eval_metric(eval_predict):
predictions, labels = eval_predict
predictions = predictions.argmax(axis=-1)
acc = acc_metric.compute(predictions=predictions, references=labels)
f1 = f1_metirc.compute(predictions=predictions, references=labels)
acc.update(f1)
return acc
train_args = TrainingArguments(output_dir="./checkpoints", # 输出文件夹
per_device_train_batch_size=32, # 训练时的batch_size
per_device_eval_batch_size=128, # 验证时的batch_size
logging_steps=10, # log 打印的频率
evaluation_strategy="epoch", # 评估策略
save_strategy="epoch", # 保存策略
save_total_limit=3, # 最大保存数
learning_rate=2e-5, # 学习率
weight_decay=0.01, # weight_decay
metric_for_best_model="f1", # 设定评估指标
load_best_model_at_end=True) # 训练完成后加载最优模型
from transformers import DataCollatorWithPadding
trainer = Trainer(model=model,
args=train_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
data_collator=DataCollatorWithPadding(tokenizer=tokenizer),
compute_metrics=eval_metric)
trainer.train()Pytorch多机多卡代码实现
上面的代码是在单机多卡的环境下实现并行训练,只需要在--nproc-per-node这个参数设置任务的并行数量。在多机环境下就不一样了,我们需要解决多机的通信问题。
我们需要指定一台机器作为主节点,这个设置由参数MASTER_ADDR决定。
这里我放上两段代码,一个是Pytorch的官方教程,使用了torchrun执行:
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = nn.Linear(10, 10)
self.relu = nn.ReLU()
self.net2 = nn.Linear(10, 5)
def forward(self, x):
return self.net2(self.relu(self.net1(x)))接下来是重点:
def demo_basic():
dist.init_process_group("nccl")
rank = dist.get_rank()
print(f"Start running basic DDP example on rank {rank}.")
# create model and move it to GPU with id rank
device_id = rank % torch.cuda.device_count()
model = ToyModel().to(device_id)
ddp_model = DDP(model, device_ids=[device_id])
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
optimizer.zero_grad()
outputs = ddp_model(torch.randn(20, 10))
labels = torch.randn(20, 5).to(device_id)
loss_fn(outputs, labels).backward()
optimizer.step()
dist.destroy_process_group()
if __name__ == "__main__":
demo_basic()在执行时,需要每个节点上都在命令行执行同样的命令,下述代码是一个例子,代表在两个机器(节点)上训练,每个机器各8个进程(GPU),共计16张GPU。
export MASTER_ADDR=localhost # 这里需要放上主节点IP
torchrun --nnodes=2 --nproc_per_node=8 --rdzv_id=100 --rdzv_backend=c10d --rdzv_endpoint=$MASTER_ADDR:29400 elastic_ddp.py执行完成后即可开始训练。
接下来是知乎上找的代码,也记录一下:
首先构建模型:
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = nn.Linear(10, 10)
self.relu = nn.ReLU()
self.net2 = nn.Linear(10, 5)
def forward(self, x):
return self.net2(self.relu(self.net1(x)))随后进入训练流程:
def train():
# 获取当前显卡的LOCAL_RANK和RANK
local_rank = int(os.environ["LOCAL_RANK"])
rank = int(os.environ["RANK"])
print(f"[{os.getpid()}] (rank = {rank}, local_rank = {local_rank}) training...")
# 构建DDP模型
model = ToyModel().cuda(local_rank)
ddp_model = DDP(model, [local_rank])
# 损失函数和优化器
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
# 前向传播并计算损失
optimizer.zero_grad()
outputs = ddp_model(torch.randn(20, 10).to(local_rank))
labels = torch.randn(20, 5).to(local_rank)
loss = loss_fn(outputs, labels)
# 后向传播,梯度更新
loss.backward()
optimizer.step()
print(f"[{os.getpid()}] (rank = {rank}, local_rank = {local_rank}) loss = {loss.item()}\n") 接下来是调用部分:
def run():
env_dict = {
key: os.environ[key]
for key in ("MASTER_ADDR", "MASTER_PORT", "WORLD_SIZE", "LOCAL_WORLD_SIZE")
}
print(f"[{os.getpid()}] Initializing process group with: {env_dict}")
dist.init_process_group(backend="nccl")
train()
dist.destroy_process_group()
if __name__ == "__main__":
run()在主节点上执行如下脚本:
--nproc_per_node=4: 表示在一个node上启动4个process--nnodes=2:表示一共有2个node进行分布式训练--node_rank=0:当前node的id为0--master_addr="192.0.0.1":主节点的地址--master_port=1234:主节点的porttrian_multi_node.py:训练代码
torchrun --nproc_per_node=4 \
--nnodes=2 \
--node_rank=0 \
--master_addr="192.0.0.1" \
--master_port=1234 \
trian_multi_node.py在子节点上执行如下脚本,唯一的区别是–node_rank设置为1:
torchrun --nproc_per_node=4 \
--nnodes=2 \
--node_rank=1\
--master_addr="192.0.0.1" \
--master_port=1234\
trian_multi_node.py运行结果如下:
主节点的执行结果:
- 2~4行:node0上四个进程的显示的全局信息
- 6~9行:node0上四个进程准备开始训练
- 10~13行:node0上四个进程完成训练,并输出loss信息
/workspace/DDP# sh run_node0.sh
[594] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '1234', 'WORLD_SIZE': '8', 'LOCAL_WORLD_SIZE': '4'}
[595] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '1234', 'WORLD_SIZE': '8', 'LOCAL_WORLD_SIZE': '4'}
[593] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '1234', 'WORLD_SIZE': '8', 'LOCAL_WORLD_SIZE': '4'}
[592] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '1234', 'WORLD_SIZE': '8', 'LOCAL_WORLD_SIZE': '4'}
[593] (rank = 1, local_rank = 1) training...
[595] (rank = 3, local_rank = 3) training...
[592] (rank = 0, local_rank = 0) training...
[594] (rank = 2, local_rank = 2) training...
[595] (rank = 3, local_rank = 3) loss = 1.12112295627594
[592] (rank = 0, local_rank = 0) loss = 1.5381203889846802
[593] (rank = 1, local_rank = 1) loss = 1.1606591939926147
[594] (rank = 2, local_rank = 2) loss = 0.973732590675354子节点的执行结果:
/workspace/DDP# sh run_node1.sh
[292] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '1234', 'WORLD_SIZE': '8', 'LOCAL_WORLD_SIZE': '4'}
[294] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '1234', 'WORLD_SIZE': '8', 'LOCAL_WORLD_SIZE': '4'}
[293] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '1234', 'WORLD_SIZE': '8', 'LOCAL_WORLD_SIZE': '4'}
[295] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '1234', 'WORLD_SIZE': '8', 'LOCAL_WORLD_SIZE': '4'}
[295] (rank = 7, local_rank = 3) training...
[292] (rank = 4, local_rank = 0) training...
[294] (rank = 6, local_rank = 2) training...
[293] (rank = 5, local_rank = 1) training...
[292] (rank = 4, local_rank = 0) loss = 1.3587342500686646
[294] (rank = 6, local_rank = 2) loss = 1.0895851850509644
[295] (rank = 7, local_rank = 3) loss = 1.1472846269607544
[293] (rank = 5, local_rank = 1) loss = 1.1993836164474487实现细节
分布式数据并行在实现中需要注意几个细节:
- 数据内一定要注意数据划分的一致,不然其他进程会用验证集去训练。因此需要设置随机种子。
- 需要用分布式采样器。
- 查看全局信息时需要记住使用通信,否则只能看到某一个进程内的信息。
- 将数据放置在设备上时需要注意使用正确的
device_id,通常会使用local_rank来指定。
2024/3/7 于苏州