近期学习了一下分布式训练,因此出一篇博客记录。
首先,如果我们只有一张显卡,我们在训练模型时能怎么解决爆显存的问题?
- 一个是从训练的参数量来处理,例如可以使用Prompt Tuning,LoRA等方法来只训练大大小于模型原参数量的参数,常用的库是PEFT。
- 另一种则是调整模型的精度,可以用半精度,Int8,Int4来让模型的大小减小,常用的库是Bitsandbytes。
当这两种方法都使用了以后还无法解决显存资源的时候,就需要使用分布式训练,利用多个节点来加速训练。通常会将计算任务和数据分发到多个节点来训练。分布式训练也通常来解决数据过大,模型过大的难题。
分布式训练
常见的分布式训练包含了几种:
- 数据并行:Data Parrallel(DP)。在每个GPU上复制一份完整的模型,但是每个GPU的训练数据不同。这也要求每张显卡都能够完整的执行训练。
- 流水线并行:Pipeline Parrallel(PP)。将模型按层拆开,每个GPU包含了部分层。这就不要求每个显卡能够完整执行训练过程。
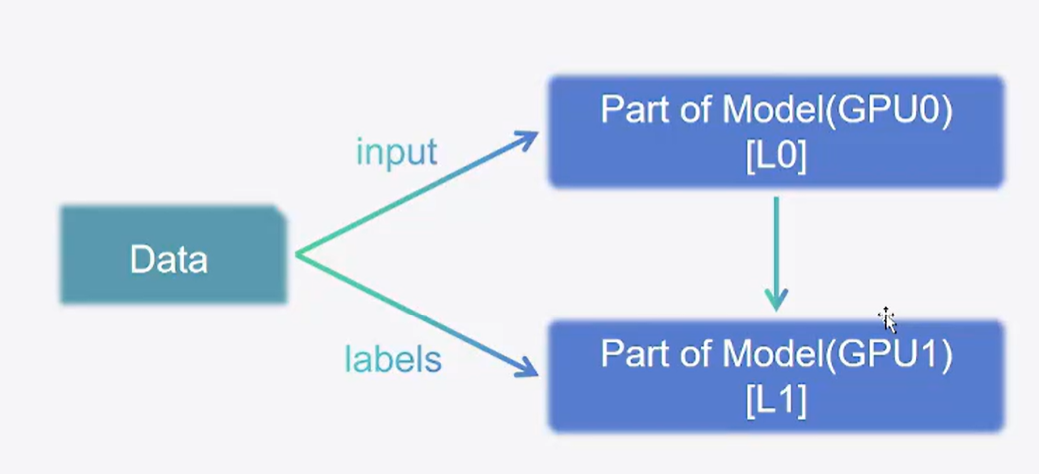
- 张量并行:Tensor Parrallel(TP)。把模型的每层权重拆开,每个GPU上放一部分权重。
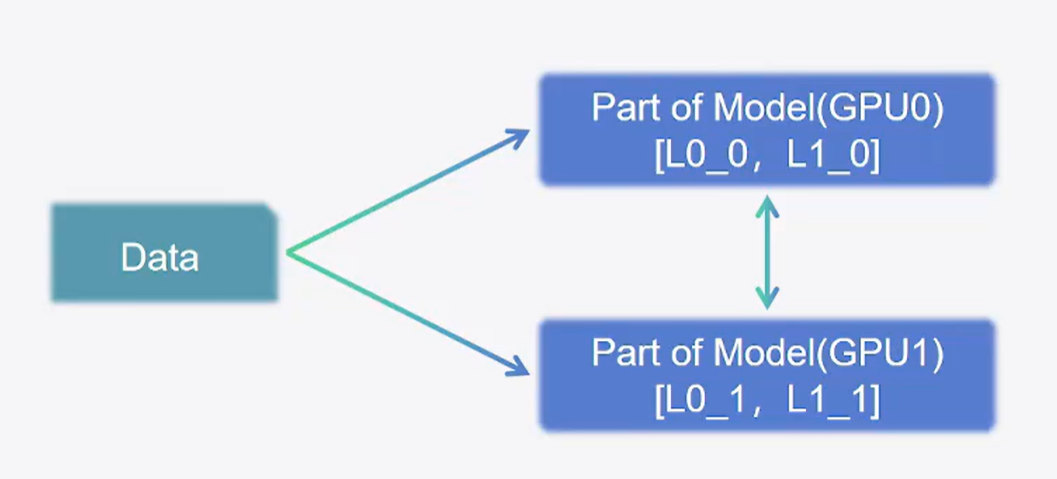
我们可以同时使用这三种策略,这时候就称为3D并行。
使用Trainer进行单机多卡训练
transformers的traner库默认是支持自动进行多卡训练的,下面给出代码。
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments, BertTokenizer, BertForSequenceClassification
from datasets import load_dataset
# 加载数据集
dataset = load_dataset("csv", data_files="./ChnSentiCorp_htl_all.csv", split="train")
dataset = dataset.filter(lambda x: x["review"] is not None)
dataset
# 划分数据集
datasets = dataset.train_test_split(test_size=0.1)
# 数据预处理
import torch
tokenizer = BertTokenizer.from_pretrained("./model")
def process_function(examples):
tokenized_examples = tokenizer(examples["review"], max_length=128, truncation=True)
tokenized_examples["labels"] = examples["label"]
return tokenized_examples
tokenized_datasets = datasets.map(process_function, batched=True, remove_columns=datasets["train"].column_names)
tokenized_datasets
# 创建模型
model = BertForSequenceClassification.from_pretrained("./model")
# 创建评估函数
import evaluate
acc_metric = evaluate.load("./metric_accuracy.py")
f1_metirc = evaluate.load("./metric_f1.py")
def eval_metric(eval_predict):
predictions, labels = eval_predict
predictions = predictions.argmax(axis=-1)
acc = acc_metric.compute(predictions=predictions, references=labels)
f1 = f1_metirc.compute(predictions=predictions, references=labels)
acc.update(f1)
return acc
# 构建TrainingArguments
train_args = TrainingArguments(output_dir="./checkpoints", # 输出文件夹
per_device_train_batch_size=64, # 训练时的batch_size
per_device_eval_batch_size=128, # 验证时的batch_size
logging_steps=10, # log 打印的频率
evaluation_strategy="epoch", # 评估策略
save_strategy="epoch", # 保存策略
save_total_limit=3, # 最大保存数
learning_rate=2e-5, # 学习率
weight_decay=0.01, # weight_decay
metric_for_best_model="f1", # 设定评估指标
load_best_model_at_end=True) # 训练完成后加载最优模型
train_args
# 创建Trainner
from transformers import DataCollatorWithPadding
trainer = Trainer(model=model,
args=train_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
data_collator=DataCollatorWithPadding(tokenizer=tokenizer),
compute_metrics=eval_metric)
# 训练
trainer.train()当开始训练时,可以看到本地的多卡都被占用了,这是因为Trainer类自己识别的本地的显卡并调用。
最后还可以评估一下模型,并进行预测。
# 模型评估
trainer.evaluate(tokenized_datasets["test"])
# 模型预测
trainer.predict(tokenized_datasets["test"])
from transformers import pipeline
id2_label = {0: "差评!", 1: "好评!"}
model.config.id2label = id2_label
pipe = pipeline("text-classification", model=model, tokenizer=tokenizer, device=0)
sen = "我觉得不错!"
pipe(sen)2024/3/5 于苏州