在推荐系统中,特征交叉和特征筛选是一个永恒不灭的话题。从逻辑回归时代的人工特征交互,到poly2的完全特征交互,到FM的隐向量特征交互,再到GDBT+LR的自动特征交互,都是在深度学习方法开始之前的特征工程的发展历史。
在14年Resnet解决了层数过深导致的梯度消失问题后,深度神经网络被广泛运用到工业界。2016年微软发布了Deep Crossing模型,用于CTR等二分类任务,原论文链接如下:Deep Crossing: Web-Scale Modeling without
论文解读
看名字就知道它要解决的是人工组合特征的问题。通过构建网络来实现特征的深度交叉。在Deep Crossing中,支持文本,分类,ID,数值这样的特征。
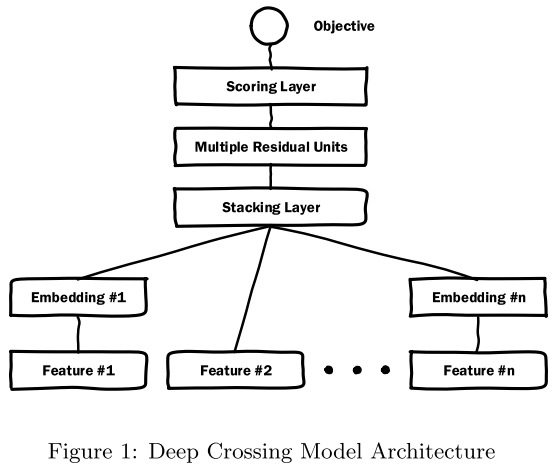
Deep Crossing的网络架构如下:
核心是四个部分:Embedding层用于嵌入特征,Stacking层用于将嵌入层简单的concat在一起,随后通过多个Residual模块提取特征。最后利用一个Scoring层来进行打分,也就是最后得到的logit值。通过对logit值进行排序,实现投放广告的排序。
原文中,微软使用的特征如下所示:
对于一些关键的概念也进行了解释:
特征
含义
搜索词
用户在搜索框中输入的搜索词
广告关键词
广告主为广告添加的描述其产品的关键词
广告标题
广告标题
落地页
点击广告后的落地页面
匹配类型 Match Type
广告主选择的广告-搜索词匹配类型(精准,模糊,语义等)
点击率
广告历史点击率
预估点击率
另一个CTR模型的CTR预估值
广告计划 Campaign
广告主创建的广告投放计划,包括预算,定向条件等
曝光样例
一个广告曝光的例子,记录了广告在实际曝光场景的相关信息
点击样例
一个广告点击的例子,记录了广告在实际点击场景的相关信息
每个单独的特征都被转为向量,例如对于Query等文本特征,将转为49292维的向量。例如匹配类型的低基数分类输入进行one hot处理。对于一些高基数的特征,例如Campaign ID特征,它表示的是不同的广告计划,通常会有数百万个ID,原作者的思路是根据CampaignID的历史点击率,选择Top10000个,编号从0到9999,将剩余的ID统一编号为10001。同时构建其衍生特征,将所有ID对应的历史点击率组合成10001维的稠密矩阵,各个元素分别为对应ID的历史CTR,最后一个元素为剩余ID的平均CTR。通过降维引入衍生特征的方式,可以有效的减少高基数特征带来的参数量剧增问题。
这也是原图中展示的Campaign ID 10001维度的由来。
文章对特征嵌入没有讲的很明确,翻阅了很多网上的解释,我对这一部分依旧不是很理解。原文针对自己的场景有一些tricks,整体的思想就是将高维稀疏矩阵嵌入为低维稠密矩阵。
嵌入层之后经过Stacking层的拼接,直接传到残差层。
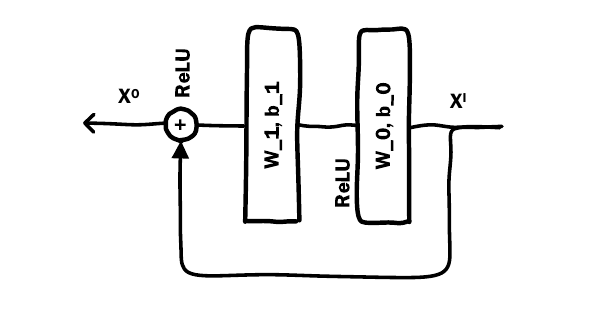
针对ResNet中的残差模块,将原本的卷积核替换为了普通的MLP层。经过多层残差后,输出一个score,用于评估用户是否会点击对应的广告。
代码实现
用pytorch实现一下代码,假设特征工程和预处理已经结束,我们需要实现数据集类,模型,训练/预测代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class CustomDataset (Dataset ):def __init__ (self, X, y=None ):def __len__ (self ):return len (self.X)def __getitem__ (self, index ):if self.y is not None :return X_item, y_itemreturn X_item32 , shuffle=True )32 , shuffle=False )
定义模型:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 class DeepCrossing (nn.Module):def __init__ (self, input_dims, embedding_dim, residual_dims, output_dim=1 ):super (DeepCrossing, self).__init__()if input_dim > embedding_dim else nn.Identity()for input_dim in input_dimssum (embedding_dim if input_dim > embedding_dim else input_dim for input_dim in input_dims)for dim in residual_dims]def forward (self, inputs ):input ) for embedding, input in zip (self.embeddings, inputs)]1 )return outclass ResidualUnit (nn.Module):def __init__ (self, input_dim, hidden_dim ):super (ResidualUnit, self).__init__()def forward (self, x ):return F.relu(out)
下面就是训练部分:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 10 8 64 , 128 , 64 , 32 ]0.001 )def train (model, train_loader, criterion, optimizer, num_epochs=10 ):for epoch in range (num_epochs):0.0 for inputs, labels in train_loader:1 ) for i in range (inputs.shape[1 ])]0 ].size(0 )len (train_loader.dataset)print (f'Epoch {epoch+1 } /{num_epochs} , Loss: {epoch_loss:.4 f} ' )
模型评估:
1 2 3 4 5 6 7 8 9 10 11 12 13 def evaluate (model, test_loader ):eval ()with torch.no_grad():for inputs, labels in test_loader:1 ) for i in range (inputs.shape[1 ])]return predictions0.5 print ("Predictions: " , predictions)
2024/8/18 于苏州