Why Decoder-Only Instead of Encoder-Only?
为什么现在的语言模型都采用Decoder Only的架构?这是一道经典面试题,这次整理一下做一个记录。
首先话不多说,先上Transformer架构图:
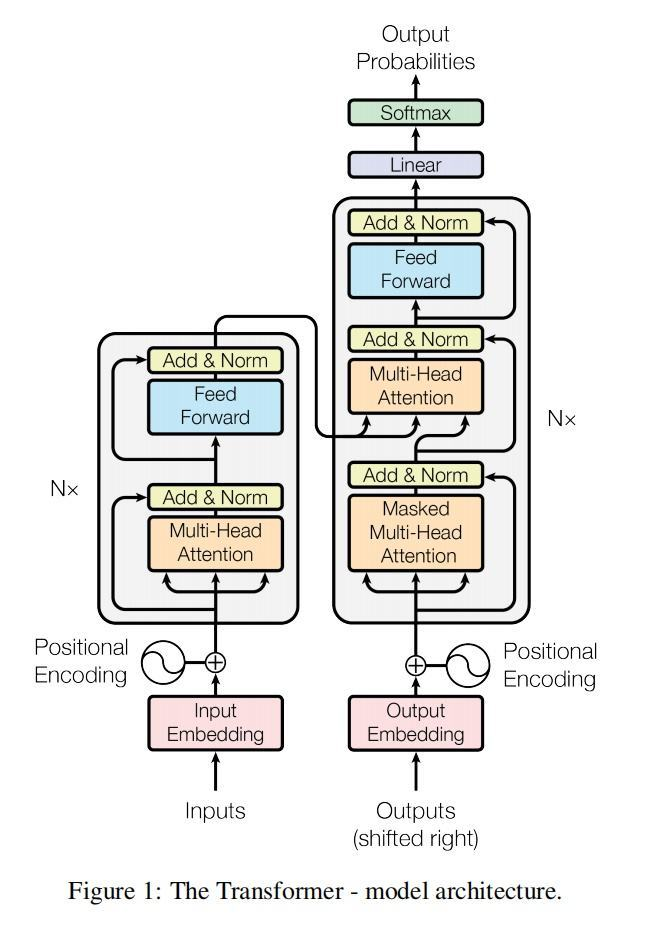
我们把处理模型输入的模型叫做Encoder,生成输出的模型叫做Decoder。Transformer的具体架构细节无需赘言,左侧是编码器Encoder,右侧是解码器Decoder。我们可以看到,去除掉网络尾部的前馈层,Decoder只比Encoder多了一个Masked后的多头注意力,也就是通过上三角矩阵遮掩掉一部分未来的信息。这时候问题就转变为,为什么语言模型都需要Masked的多头注意力?
文本生成
首先,需要明确的是,Encoder在整个网络的架构中,负责将输入的信息转化为高维的内部表示,而Decoder负责根据这个内部表示,生成下一个概率最大的Token。从两者任务上来看,生成式语言模型更加关注于后者的生成特性,对于前者的编码特性并不是那么关注。
与之相对的是经典的Bert,被用来做文本分类,情感分析等任务。它的架构是Encoder Only,由于它的任务更专注于输出的信息,因此它并不用来生成文本。
而从语言学的角度来看,我们在每次说话的时候,每说出一个字,都需要考虑到前面已经说出的内容,而非完整内容,这也是为什么需要Mask的原因。
训练与推理效率
由于每次只生成下一个Token的特性,语言模型每次生成,都需要完整单独执行一遍模型推理,去除Encoder也是为了计算效率的考究。如果只需要输入的高维表示,则Encoder自身的Embedding层已经足矣。减少了一半的参数,这样在训练和推理时都大大减少了计算复杂度和空间复杂度。
低秩
这个想法来自于苏剑林老师,Attention矩阵由一个𝑛×𝑑的矩阵与𝑑×𝑛的矩阵相乘后再加上softmax来得到,由于其中的𝑛远大于𝑑,因此可以认为这个矩阵中有很多无意义的部分。而Decoder中的Attention矩阵经过Mask,变成了下三角矩阵,三角阵的行列式等于对角线元素之积,由于softmax的存在,对角线必然都是正数,所以它的行列式必然是正数,即Decoder-only架构的Attention矩阵一定是满秩的。
其中𝑛是序列长度,𝑑是head_size,在多头注意力中,head_size = hidden_size / heads,比如BERT base中head_size = 768 / 12 = 64,而预训练长度𝑛一般为512,所以𝑛≫𝑑大致上都是成立的。
满秩说明信息更被充分利用,因此理论上表达能力更强。
总结一下,使用Decoder的原因主要如下:
- Encoder的Attention存在低秩问题
- 工程上Decoder Only的参数量和推理成本更佳
最后,把早先我发在脉脉上的帖子再复制一遍放在这里:
解码器能用在大语言模型上吗?查阅了资料总结了一下:
- 只有编码器的模型通常预训练任务都是学习输入语言的表示,比如通过上下文,判断缺失的单词部分,做完形填空和预测句子对,因此不太适合用于生成语言任务(因为生成语言任务中没有下文,只有上文)
- GLM是在解码器的基础上加上了Prefix掩码,这个Prefix的思想来源于Encoder模型
- 也有用同时使用编码器-解码器的语言模型(T5),但是从运行效率上,参数量多了一倍,推理和训练速度都会增加
- 从训练角度分析,纯解码器模型在训练后,zeroshot的生成任务效果更好,也更符合对话模型causal model的任务逻辑。而编码-解码器需要在子任务上微调才可以表现更好(因为本身预训练的时候就需要在有上下文,所以一般只用它的思想,也就是在解码器模型上加掩码)
2024/6/12 于苏州