2023年12月8日,来自欧洲的团队Mistral AI团队发布了他们的新开源模型:Mixtral 8x7B。他们发布的方式也是别具一格,直接甩出一条87G文件的磁力链接。
值得一提的是,这家位于巴黎的公司上一次发布的Mistral 7B模型,也是直接发的磁力链接,并且把LLama2 13B作为基准碾压了一遍。
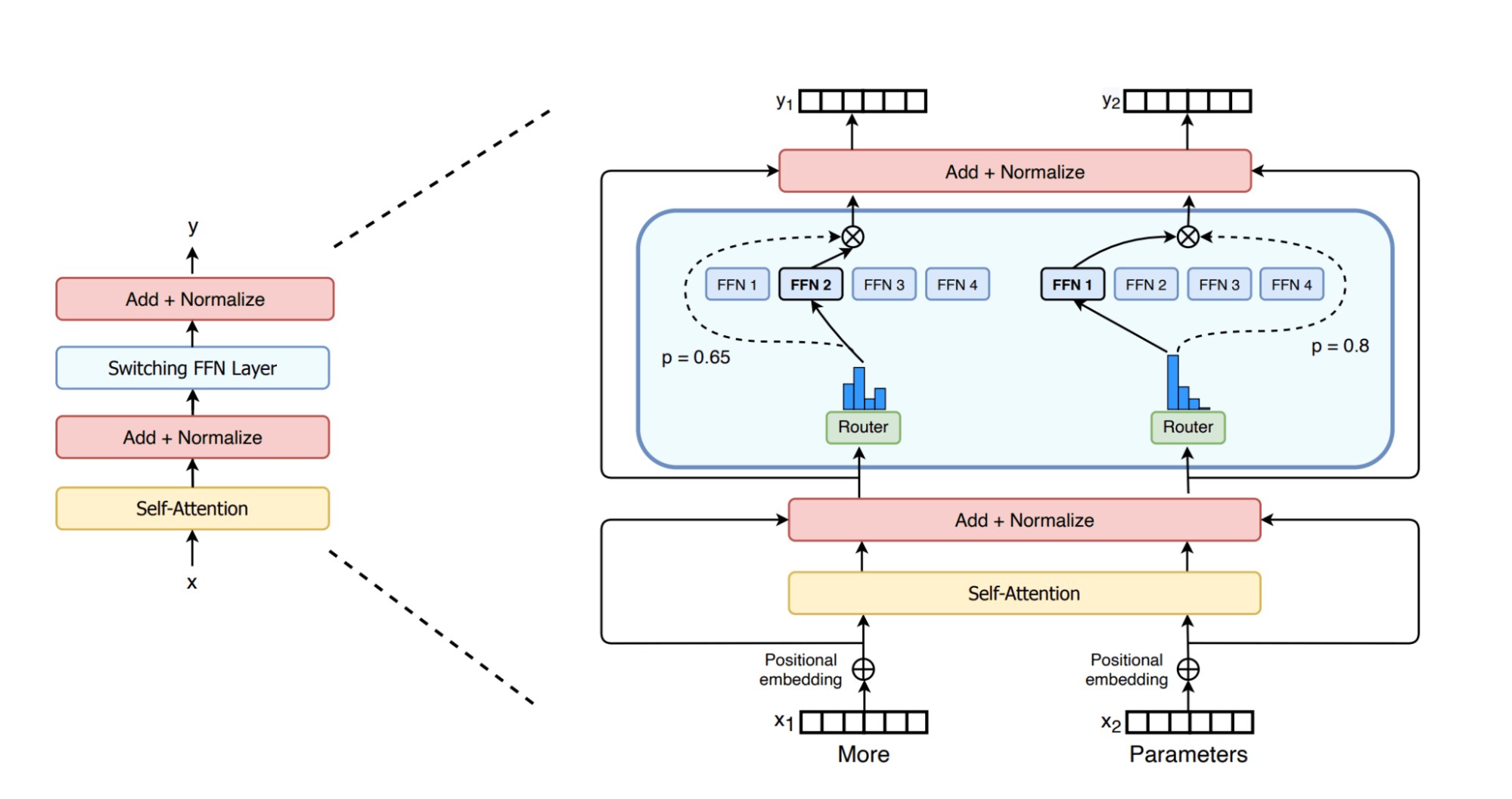
模型架构 Mixtral采用了SMoE(稀疏混合专家模型)架构,把原来的前馈层改成了一个路由网络,用来给8个并行的子层进行分配Token。这里的子层就被称为专家。由于运行时不是所有参数都会进行推理,因此这个架构被称为稀疏架构,这也是名字中S(Sparse)的由来。
Mixtral共拥有8个专家,每个专家参数为7B。由于存在共享参数,模型的总参数为47B而非56B。
其实由上你也可以看出来,这个架构解决的主要还是推理速度,而非显存占用,因为47B参数在运行时依旧需要先加载进入显存。
原文翻译 由于Mixtral 8x7B目前还没有发布论文,我们可以解读一下团队发布的博客。
Mistral AI 继续履行着它创立以来的使命,为开发者社区提供最佳的开源模型。人工智能的发展需要采取新的技术转向,而不是重复使用众所周知的架构和训练范式。最重要的是,它应该让社区能从原始模型中受益,以促进新的发明和使用。
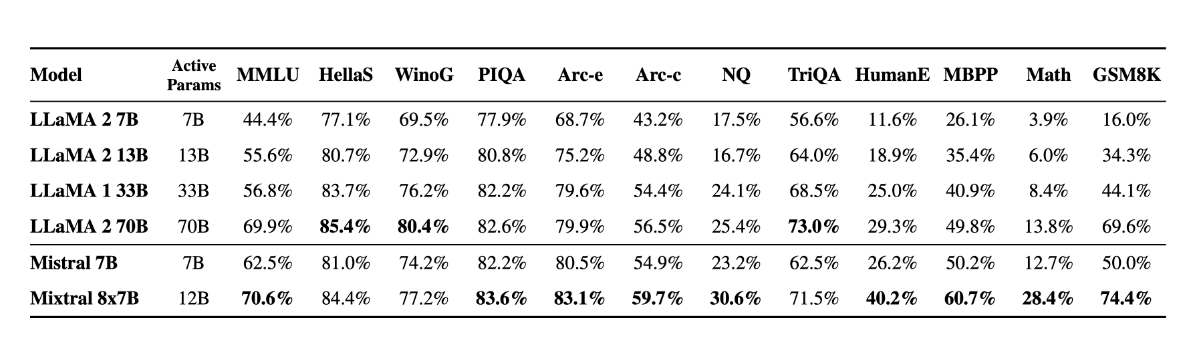
今天,我们自豪地发布了 Mixtral 8x7B,这是一个高质量稀疏专家混合模型 (SMoE),且权重已经开源 。该模型的许可证是Apache 2.0 。Mixtral 在大多数基准测试中的表现优于 Llama 2 70B,且推理速度提高了 6 倍 。它是目前的最强开源模型,也是成本/性能权衡方面整体上的最佳模型。重点是,它在大多数标准基准测试上都与 GPT3.5 相当或优于 GPT3.5。
Mixtral 具有以下特性:
它能够处理 32k Token的上下文。
它能够处理英语、法语、意大利语、德语和西班牙语。
它在代码生成方面性能强大。
通过对它进行微调,转换为指令遵循(instruaction-following)模型,在 MT-Bench 上能达到 8.3 分。
走在推广稀疏架构的开源模型的前沿 Mixtral 是一个稀疏的专家混合网络(sMoE, sparse mixture-of-experts)。这是一种仅解码器(decoder-only)模型,其中前馈模块(Feed Forward,即全连接层)从一组 8 组不同的参数中进行选择。在每一层,对于每个Token,有一个路由(Router)网络都会选择其中8组参数中的两个组(也就是“专家”)来处理Token并将其的输出进行累加组合。
这种技术在增加了参数数量的情况下,控制了成本和延迟,因为模型只需要使用每个Token参数集中总数的一小部分。具体来说,Mixtral 有 46.7B 的总参数,但每个Token只使用 12.9B 参数。因此它的推理速度应当与 12.9B 模型相同。
Mixtral 使用从开放网络中提取的数据进行预训练——这一过程中将同时训练“专家”和“路由”。
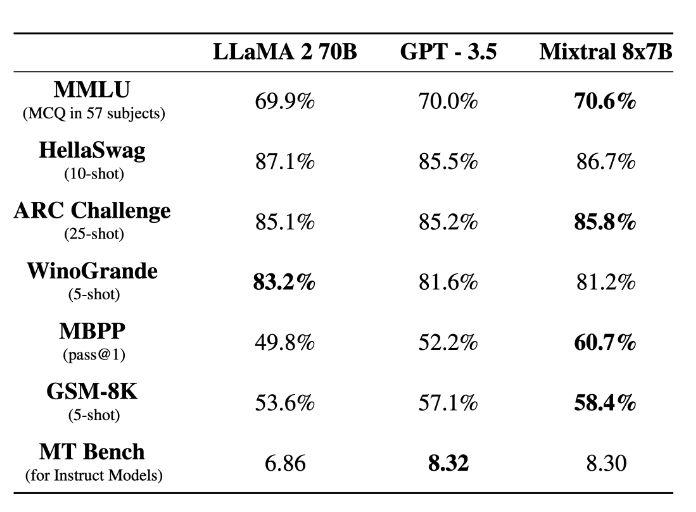
性能 我们将 Mixtral 与 Llama 2 系列和 GPT3.5 基本型号进行了比较。在大多数基准测试中,Mixtral 都达到或优于 Llama 2 70B 和 GPT3.5。
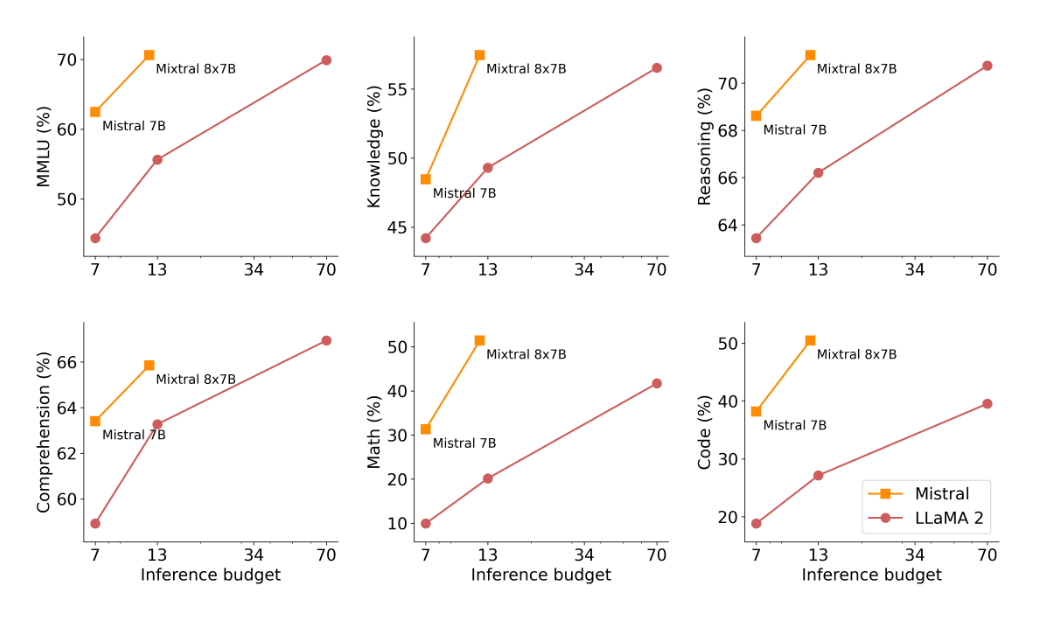
在下图中,我们衡量了模型质量与推理预算的权衡。与 Llama 7 型号相比,Mistral 8B 和 Mixtral 8x7B 属于更高效的模型。
下表给出了上图的详细结果。
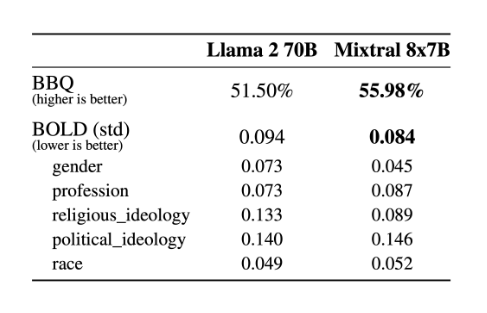
模型幻觉和偏见 为了识别可能通过微调/偏好建模来纠正的缺陷,我们在BBQ/BOLD上评估了基本模型的性能。
与 Llama 2 相比,Mixtral 在 BBQ 基准测试上的偏差较小。总体而言,Mixtral 在 BOLD 上表现出比 Llama 2 更积极的情绪,且每个维度的差异都较一致,不存在偏科的情况。
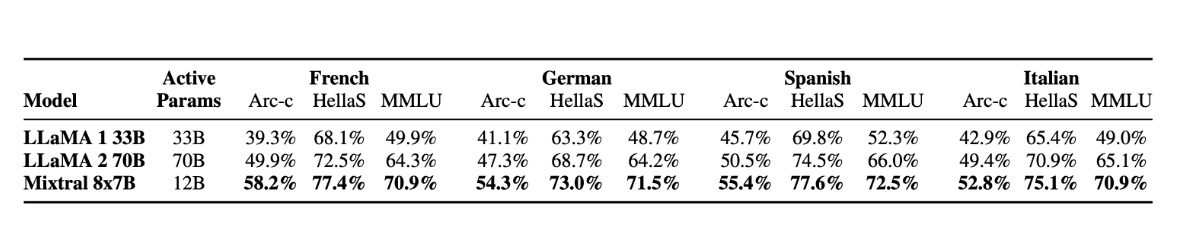
语言 Mixtral 8x7B 精通法语、德语、西班牙语、意大利语和英语。
指导模型 我们发布了 Mixtral 8x7B Instruct 和 Mixtral 8x7B。它们通过监督微调和直接偏好优化 (DPO) 进行了优化,以便仔细遵循人类给出的指令。在 MT-Bench 上,它的得分达到了 8.30,使其成为当前最好的开源模型,性能可与 GPT3.5 相媲美。
使用开源部署堆栈部署 Mixtral 为了使社区能够使用完全开源的堆栈运行 Mixtral,我们提交了对 vLLM 项目的更改,该项目集成了 Megablocks CUDA 内核以实现高效推理。
关于Mistral AI
在人工智能成为风口的当下,这家公司在六个月内就筹集了1.12亿美元的融资,且A轮融资已经筹集了3.85亿欧元,这也让Mistral AI的估值达到约20亿美元,自6月份首次亮相以来,其估值已增长超过七倍,成为欧洲最成功的大模型公司。
公司的核心创始人是Arthur Mensch(CEO), Timothée Lacroix(CTO)和Guillaume Lample(Chief Scientist),CEO来自于Google DeepMind,后两者都来自于MetaAI,且均在LLama模型中做出了重大贡献。
使用QLoRA对Mixtral模型微调 参考了一些示例代码,写了下微调的示例代码。
1 2 3 4 5 6 7 8 9 10 11 12 import torchfrom datasets import load_datasetfrom peft import LoraConfig, PeftModel, prepare_model_for_kbit_trainingfrom transformers import (from trl import SFTTrainer
1 2 3 4 5 6 7 model_name = "mistralai/Mixtral-8x7B-v0.1" True , use_fast=True )'left'
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def format_ultrachat (ds ):for row in ds:if len (row['messages' ]) > 2 :"### Human: " +row['messages' ][0 ]['content' ]+"### Assistant: " +row['messages' ][1 ]['content' ]+"### Human: " +row['messages' ][2 ]['content' ]+"### Assistant: " +row['messages' ][3 ]['content' ])else : "### Human: " +row['messages' ][0 ]['content' ]+"### Assistant: " +row['messages' ][1 ]['content' ])"text" , column=text)return ds"HuggingFaceH4/ultrachat_200k" , split="train_sft" )"HuggingFaceH4/ultrachat_200k" , split="test_sft[:5%]" )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 getattr (torch, "float16" )True ,"nf4" ,True ,"" : 0 }False
1 2 3 4 5 6 7 8 peft_config = LoraConfig(64 ,0.1 ,16 ,"none" ,"CAUSAL_LM" ,'k_proj' , 'q_proj' , 'v_proj' , 'o_proj' ]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 "./results_mixtral_sft/" ,"steps" ,True ,"paged_adamw_8bit" ,8 ,2 ,8 ,"debug" ,50 ,50 ,2e-5 ,50 ,300 ,30 ,"linear" ,
1 2 3 4 5 6 7 8 9 10 11 12 13 "text" ,512 ,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 "Hello my name is" "pt" )20 )print (tokenizer.decode(outputs[0 ], skip_special_tokens=True ))'yang_zhou/mixtral' del model, trainer"" : 0 }'yang_zhou/mixtral/ft_model'
2023/12/30 于昆山